Chaque bibliothèque au sein de Subversion peut être classée
dans une des trois couches principales : la couche dépôt, la
couche d'accès au dépôt (RA pour Repository
Access en anglais) et la couche client (voir la
Figure 1, « L'architecture de Subversion » de la préface).
Nous allons examiner ces trois couches rapidement mais, d'abord,
passons brièvement en revue les différentes bibliothèques de
Subversion. Pour des raisons de cohérence, nous nous référons à
ces bibliothèques par leurs noms Unix sans extension
(libsvn_fs, libsvn_wc,
mod_dav_svn, etc.).
- libsvn_client
-
interface principale pour les programmes clients ;
- libsvn_delta
-
routines de recherche de différences pour les arborescences et les flux d'octets ;
- libsvn_diff
-
routines de recherche de différences et de fusions contextuelles ;
- libsvn_fs
-
chargeur de modules et outils communs pour le système de fichiers ;
- libsvn_fs_base
-
gestion du magasin de données Berkeley DB ;
- libsvn_fs_fs
-
gestion du magasin de données natif FSFS ;
- libsvn_ra
-
outils communs pour l'accès au dépôt et chargeur de modules ;
- libsvn_ra_local
-
module d'accès au dépôt en local ;
- libsvn_ra_serf
-
autre module (expérimental) d'accès au dépôt par le protocole WebDAV ;
- libsvn_ra_svn
-
modèle d'accès au dépôt par le protocole Subversion ;
- libsvn_repos
-
interface du dépôt ;
- libsvn_subr
-
diverses routines utiles ;
- libsvn_wc
-
bibliothèque pour la gestion de la copie de travail locale ;
- mod_authz_svn
-
module Apache d'authentification pour les accès aux dépôts Subversion par WebDAV ;
- mod_dav_svn
-
module Apache de correspondance entre les opérations WebDAV et les opérations Subversion.
Le fait que le mot « divers » n'apparaisse qu'une seule fois dans la liste précédente est plutôt un bon signe. L'équipe de développement de Subversion est particulièrement soucieuse de placer les fonctionnalités dans les couches et bibliothèques appropriées. Un des plus grands avantages de cette conception modulaire, du point de vue du développeur, est sûrement l'absence de complexité. En tant que développeur, vous pouvez vous forger rapidement une image mentale de cette architecture et ainsi trouver relativement facilement l'emplacement des fonctionnalités qui vous intéressent.
Un autre avantage de la modularité est la possibilité de
remplacer un module par une autre bibliothèque qui implémente la
même API sans affecter le reste du code. Dans un certain sens,
c'est ce qui se passe déjà dans Subversion. Les bibliothèques
libsvn_ra_local,
libsvn_ra_serf et
libsvn_ra_svn implémentent toutes la même
interface et fonctionnent comme des greffons pour
libsvn_ra. Et toutes les trois communiquent
avec la couche dépôt — libsvn_ra_local
se connectant directement au dépôt, les trois autres le faisant à
travers le réseau.
libsvn_fs_base et
libsvn_fs_fs sont un autre exemple de
bibliothèques qui implémentent les mêmes fonctionnalités de
différentes manières — les deux sont des greffons pour la
bibliothèque commune libsvn_fs.
Le client lui-même illustre également les avantages de la
modularité dans l'architecture de Subversion. La bibliothèque
libsvn_client est un point d'entrée unique
pour la plupart des fonctionnalités nécessaires à la conception
d'un client Subversion fonctionnel (voir la section intitulée « Couche client »). Ainsi, bien que la
distribution Subversion fournisse seulement le programme en ligne
de commande svn, de nombreux programmes tiers
fournissent différents types d'IHM. Ces interfaces graphiques
utilisent la même API que le client en ligne de commande fourni en
standard. Depuis le début, cette modularité joue un rôle majeur
dans la prolifération des différents clients Subversion, sous la
forme de clients autonomes ou greffés dans des environnements de
développement intégrés (IDE en
anglais) et, par extension, dans l'adoption formidablement rapide
de Subversion lui-même.
Quand nous faisons référence à la couche
dépôt de Subversion, nous parlons généralement de deux
concepts de base : l'implémentation du système de fichiers suivi
en versions (auquel on accède via
libsvn_fs et qui est supporté par les
greffons associés libsvn_fs_base et
libsvn_fs_fs) et la logique du dépôt qui
l'habille (telle qu'elle est implémentée dans
libsvn_repos). Ces bibliothèques
fournissent les mécanismes de stockage et de comptes-rendus pour
les différentes révisions de vos données suivies en versions.
Cette couche est connectée à la couche client
via la couche d'accès au dépôt et est,
du point de vue de l'utilisateur de Subversion, le « truc à
l'autre bout de la ligne ».
Le système de fichiers Subversion n'est pas un système de fichiers de bas niveau que vous pourriez installer sur votre système d'exploitation (tels que NTFS ou ext2 pour Linux) mais un système de fichiers virtuel. Plutôt que de stocker les fichiers et répertoires comme des fichiers et des répertoires réels (du type de ceux dans lesquels vous naviguez avec votre navigateur de fichiers), il utilise un des deux magasins de données abstraits disponibles : soit le système de gestion de bases de données Berkeley DB, soit une représentation dans des fichiers ordinaires, dite « à plat » (pour en apprendre plus sur les deux magasins de données, reportez-vous à À propos des magasins de données). La communauté de développement Subversion a même exprimé le souhait que les futures versions de Subversion puissent utiliser d'autres magasins de données, peut-être à travers un mécanisme tel que ODBC (Open Database Connectivity, standard ouvert de connexion à des bases de données). En fait, Google a fait quelque chose de semblable avant de lancer le service « Google Code Project Hosting » (Hébergement de code source de projets) : ils ont annoncé mi-2006 que les membres de leur équipe open source avaient écrit un nouveau greffon propriétaire de système de fichiers pour Subversion, qui utilisait leur base de données « Google ultra-scalable Bigtable » comme magasin de données.
L'API du système de fichiers, mise à disposition par
libsvn_fs, contient les fonctionnalités que
vous pouvez attendre de n'importe quel autre système de
fichiers : vous pouvez créer et supprimer des fichiers et
des répertoires, les copier et les déplacer, modifier le contenu
d'un fichier, etc. Elle possède également des caractéristiques
peu communes comme la capacité d'ajouter, modifier et supprimer
des méta-données (« propriétés ») sur chaque fichier
ou répertoire. En outre, le système de fichiers Subversion est
un système de fichiers suivi en versions, ce qui veut dire que
si vous faites des modifications dans votre arborescence,
Subversion se souvient de l'état de votre arborescence avant les
modifications. Et il se souvient aussi de l'état avant les
modifications précédentes, et de l'état encore antérieur, et ainsi
de suite. Vous pouvez ainsi remonter le temps (c'est-à-dire les
versions) jusqu'au moment où vous avez commencé à ajouter des
éléments dans le système de fichiers.
Toutes les modifications faites sur l'arborescence ont pour contexte les transactions de propagation de Subversion. Ce qui suit est la démarche générale simplifiée de modification du système de fichiers :
-
commencer une transaction de propagation de Subversion ;
-
effectuer les modifications (ajouts, suppressions, modifications de propriétés, etc.) ;
-
clore la transaction.
Une fois que la transaction est terminée, les modifications du système de fichiers sont stockées de façon permanente en tant qu'éléments de l'historique. Chacun de ces cycles génère une nouvelle révision de l'arborescence et chaque révision est accessible pour toujours sous la forme d'un cliché, immuable, de l'état de l'arborescence à un moment précis.
La majeure partie des fonctionnalités offertes par l'interface du
système de fichiers traite d'actions relatives à un chemin unique du
système de fichiers. C'est-à-dire que, vu de l'extérieur du système
de fichiers, le mécanisme de base pour décrire et accéder à une
révision donnée d'un fichier ou d'un répertoire utilise des chemins
classiques tels que /machin/bidule, de la même
manière que quand vous indiquez un fichier ou un répertoire dans
votre interface en ligne de commande favorite. Vous ajoutez de
nouveaux fichiers ou répertoires en passant leur
« futur » chemin à la fonction idoine de l'API. Vous
faites des requêtes sur ces éléments avec le même
mécanisme.
Cependant, contrairement à la plupart des systèmes de fichiers, le chemin n'est pas une information suffisante pour identifier un fichier ou un répertoire dans Subversion. Représentez-vous l'arborescence des répertoires comme un système à deux dimensions, où l'on atteint les frères d'un nœud en se déplaçant horizontalement, à droite ou à gauche, et où la navigation dans les sous-répertoires de ce nœud peut être assimilée à un mouvement vers le bas. La Figure 8.1, « Fichiers et répertoires en deux dimensions » illustre ce concept pour une arborescence classique.
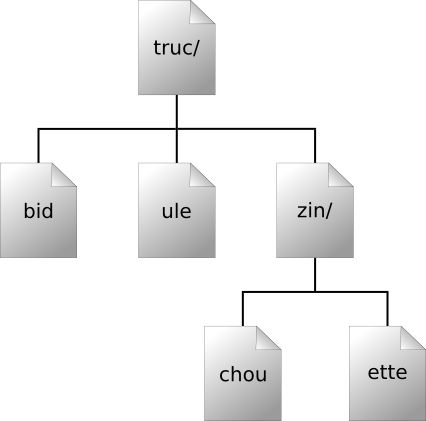
Ici, la différence est que le système de fichiers Subversion
possède une élégante troisième dimension que la plupart des
systèmes de fichiers n'ont pas : le temps[77]. Dans l'interface du système de
fichiers, presque chaque fonction qui demande un argument de type
chemin attend également un argument de type
racine (dénommé en fait
svn_fs_root_t). Cet argument décrit soit une
révision, soit une transaction (qui est en fait la genèse d'une
révision) et fournit la troisième dimension, l'élément de contexte
indispensable pour différencier /machin/bidule
dans la révision 32 et le même chemin dans la révision 98. La Figure 8.2, « Prise en compte du temps — la troisième dimension de la
gestion de versions ! » présente l'historique
des révisions comme une dimension supplémentaire de l'univers du
système de fichiers Subversion.
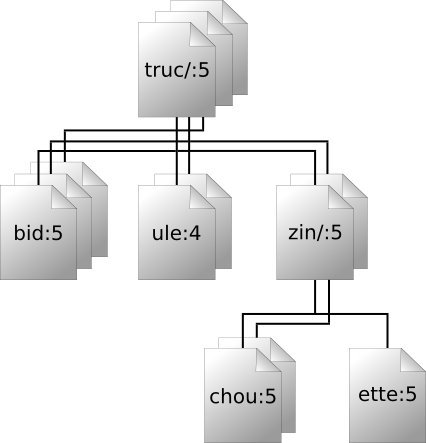
Comme nous l'avons déjà mentionné, l'API de
libsvn_fs ressemble à s'y méprendre à celle
de n'importe quel autre système de fichiers, sauf qu'on y a ajouté la
formidable capacité de gestion des versions. Elle a été conçue pour
être utilisable par n'importe quel programme ayant besoin d'un
système de fichiers suivi en versions. Et ce n'est pas un hasard si
Subversion lui-même est intéressé par une telle fonctionnalité. Mais,
bien que cette API soit suffisante pour effectuer une gestion de
versions basique des fichiers et des répertoires, Subversion en
demande plus, et c'est là que libsvn_repos entre
en scène.
La bibliothèque du dépôt Subversion
(libsvn_repos) se situe (logiquement parlant)
au-dessus de l'API libsvn_fs et elle fournit des
fonctionnalités supplémentaires allant au-delà de la logique
sous-jacente du système de fichiers suivi en versions. Elle ne masque
pas entièrement chaque fonction du système de fichiers — seules
certaines étapes importantes dans le cycle général de l'activité du
système de fichiers sont encapsulées par l'interface du dépôt. Parmi
les fonctions encapsulées, on peut citer la création et la
propagation des transactions Subversion et la modification des
propriétés de révisions. Ces actions particulières sont encapsulées
par la couche dépôt parce qu'elles ont des procédures automatiques
associées. Le système des procédures automatiques du dépôt n'est
pas strictement concomitant à l'implémentation d'un système de
fichiers suivi en versions, c'est pourquoi il réside dans la
bibliothèque d'encapsulation du dépôt.
Le mécanisme des procédures automatiques n'est pas l'unique
raison qui a conduit à séparer logiquement la bibliothèque du
dépôt du reste du code du système de fichiers. L'API de
libsvn_repos fournit à Subversion un
certain nombre d'autres possibilités intéressantes. Parmi elles,
on peut citer :
-
créer, ouvrir, détruire et effectuer des actions de restauration sur un dépôt Subversion et le système de fichiers inclus dans ce dépôt ;
-
décrire les différences entre deux arborescences ;
-
obtenir les commentaires de propagation associés à toutes les révisions (ou certaines) qui ont modifié un ensemble de fichiers du système de fichiers ;
-
générer des images (« dumps ») du système de fichiers lisibles par l'utilisateur — ces images étant des représentations complètes des révisions du système de fichiers ;
-
analyser ces images et les charger dans un autre dépôt Subversion.
Comme Subversion continue à évoluer, la bibliothèque du dépôt grandit avec la bibliothèque du système de fichiers pour offrir davantage de fonctionnalités et des options configurables.
Si la couche Dépôt de Subversion est « à l'autre
bout de la ligne », la couche d'accès au dépôt (RA pour
repository access en anglais)
est la ligne en tant que telle. Chargée d'organiser les données
entre les bibliothèques client et le dépôt, cette couche inclut
la bibliothèque de chargement du module
libsvn_ra, les modules RA eux-mêmes (qui
incluent à l'heure actuelle libsvn_ra_local,
libsvn_ra_serf et
libsvn_ra_svn) et toute bibliothèque
supplémentaire requise par un ou plusieurs de ces modules RA
(par exemple, le module Apache mod_dav_svn
ou le serveur de libsvn_ra_svn,
svnserve).
Comme Subversion utilise les URL pour identifier les
dépôts à contacter, la partie de l'URL qui indique le protocole
(habituellement file://,
http://, https://,
svn:// ou svn+ssh://) est
utilisée pour déterminer quel module RA gère les communications.
Chaque module indique la liste des protocoles qu'il connaît afin que
le chargeur RA puisse déterminer, à l'exécution, quel module utiliser
pour la tâche en cours. Vous pouvez obtenir la liste des modules RA
disponibles pour votre client Subversion en ligne de commande,
ainsi que les protocoles qu'ils prennent en charge, en lançant
la commande svn --version :
$ svn --version svn, version 1.8.16 (r1740329) compiled Apr 29 2016, 17:10:07 Copyright (C) 2016 The Apache Software Foundation. This software consists of contributions made by many people; see the NOTICE file for more information. Subversion is open source software, see http://subversion.apache.org/ Les modules d'accès à un dépôt (RA) suivants sont disponibles : * ra_svn : Module d'accès à un dépôt avec le protocole réseau propre de svn. - avec authentification Cyrus SASL - gère le schéma d'URL 'svn' * ra_local : Module d'accès à un dépôt sur un disque local. - gère le schéma d'URL 'file' * ra_serf : Module for accessing a repository via WebDAV protocol using serf. - using serf 1.3.8 - gère le schéma d'URL 'http' - gère le schéma d'URL 'https' $
L'API publique exportée par la couche RA contient les
fonctionnalités nécessaires pour envoyer des données suivies en
versions vers le dépôt et pour en recevoir. Chacun des greffons
RA disponibles est capable d'effectuer ces tâches en utilisant
un protocole particulier : libsvn_ra_dav
utilise le protocole HTTP/WebDAV (avec chiffrement SSL en
option) pour communiquer avec un serveur HTTP Apache sur lequel
tourne le module serveur Subversion
mod_dav_svn ;
libsvn_ra_svn utilise un protocole réseau
propre à Subversion pour communiquer avec le programme
svnserve, et ainsi de suite.
Ceux qui désirent accéder à un dépôt Subversion en utilisant un autre protocole comprendront rapidement pourquoi la couche d'accès au dépôt est modulaire ! Les développeurs peuvent tout simplement écrire une nouvelle bibliothèque qui implémente l'interface RA d'un côté et qui communique avec le dépôt de l'autre. Votre nouvelle bibliothèque peut utiliser des protocoles réseaux existants ou vous pouvez en inventer de nouveaux. Vous pouvez ainsi utiliser les communications inter-processus (IPC pour interprocess communication en anglais) ou même, soyons fou, implémenter un protocole basé sur l'email. Subversion apporte les API, à vous d'apporter la créativité.
Côté client, tout se passe dans la copie de travail Subversion. Le gros des fonctionnalités implémentées par les bibliothèques client existe dans le seul but de gérer les copies de travail locales — des répertoires pleins de fichiers et d'autres sous-répertoires qui sont une sorte de copie locale et modifiable d'un ou plusieurs dépôts — et de propager les changements vers et depuis la couche d'accès au dépôt.
La bibliothèque de Subversion pour la copie de travail,
libsvn_wc, est directement responsable de
la gestion des données dans les copies de travail. Pour ce
faire, la bibliothèque stocke dans un sous-répertoire spécial
des données d'administration relatives à la copie de travail.
Ce sous-répertoire, nommé .svn, est présent dans
chaque copie de travail ; il contient tout un tas de
fichiers et de répertoires qui enregistrent l'état de la copie de
travail et fournit un espace privé pour les actions
d'administration. Pour les habitués de CVS, ce sous-répertoire
.svn a des objectifs similaires aux
répertoires administratifs CVS que l'on
trouve dans les copies de travail CVS.
La bibliothèque client de Subversion,
libsvn_client, est celle qui a le plus de
responsabilités : son rôle est de mélanger les
fonctionnalités de la bibliothèque de la copie de travail avec
celles de la couche d'accès au dépôt (RA) afin de fournir l'API
de plus haut niveau, utilisable par n'importe quelle application
qui voudrait effectuer des actions générales de gestion de
versions. Par exemple, la fonction
svn_client_checkout() prend une URL en
argument. Elle passe cette URL à la couche RA et ouvre une
session authentifiée avec le dépôt concerné. Elle demande
ensuite au dépôt l'arborescence requise, envoie cette
arborescence à la bibliothèque de la copie de travail, qui
écrit alors une copie de travail complète sur le disque (les
répertoires .svn et tout le reste).
La bibliothèque client est conçue pour être utilisée par
n'importe quelle application. Alors que le code source de
Subversion inclut un client standard en ligne de commande, le
but recherché est qu'il soit très facile d'écrire un nombre
quelconque de clients dotés d'un environnement graphique
(GUI en anglais) par-dessus
cette bibliothèque client. Il n'y a pas de raison que les
nouveaux environnements graphiques (ou les nouveaux clients en
fait) pour Subversion ne soient que des sur-couches au client
en ligne de commande : ils ont un accès total, via
l'API libsvn_client, aux mêmes
fonctionnalités, données et autres mécanismes que le client en
ligne de commande utilise. En fait, le code source de Subversion
contient un petit programme en C (que vous pouvez trouver dans
tools/examples/minimal_client.c) qui montre
comment utiliser en pratique l'API Subversion pour créer un
programme client simple.
[77] Nous comprenons que cela puisse être un choc énorme pour les amateurs de science-fiction, qui ont longtemps cru que le Temps était en fait la quatrième dimension. Nous nous excusons pour le traumatisme psychologique causé par l'affirmation de cette théorie divergente.
