Subversion est un logiciel libre de la catégorie systèmes de gestion de versions (VCS en anglais, pour Version Control System). Cela signifie que Subversion gère les fichiers et les répertoires, ainsi que les changements dont ils font l'objet, à travers le temps. Vous pouvez ainsi retrouver d'anciennes versions de vos données ou parcourir l'historique des changements de vos données. Cela fait dire à certains que les systèmes de gestion de versions sont en quelque sorte des « machines à remonter le temps ».
Subversion peut fonctionner en réseau, ce qui autorise un partage des données sur des ordinateurs différents. D'une certaine manière, la possibilité pour un groupe de personnes de modifier et gérer le même ensemble de données en restant derrière son propre poste de travail renforce la collaboration. Le travail peut avancer sans nécessiter un circuit unique de validation. Et comme ce qui est réalisé est suivi en versions, vous n'avez pas à craindre que la disparition du circuit de validation ne se fasse au détriment de la qualité— si de mauvaises données sont entrées, vous n'avez qu'à annuler la modification.
Certains systèmes de gestion de versions sont aussi des systèmes de gestion de configuration logicielle (GCL). Ces systèmes sont spécialement conçus pour gérer des arborescences de code source et possèdent de nombreuses fonctionnalités propres au développement logiciel, comme la reconnaissance des langages de programmation ou des outils de construction/compilation de logiciel. Subversion, cependant, ne fait pas partie de cette catégorie. C'est un système généraliste qui peut être utilisé pour gérer n'importe quel ensemble de fichiers. Pour vous ce peut être du code source ; pour d'autres cela va de la liste de courses jusqu'aux vidéos des vacances et bien au-delà.
Si, en tant qu'utilisateur ou administrateur système, vous réfléchissez à la mise en place de Subversion, la première question à vous poser est :« est-ce bien l'outil adéquat pour ce que je veux faire ? » Subversion est un marteau fantastique, mais il faut faire attention à ne pas assimiler tout problème à un clou.
En premier lieu, vous devez décider si la gestion de versions en général répond à votre besoin. Si vous voulez archiver de vieilles versions de vos fichiers et dossiers, éventuellement de les ressusciter, ou d'examiner les journaux détaillant leurs évolutions, les systèmes de gestion de versions le font très bien. Si vous avez besoin de travailler sur des documents en collaboration avec d'autres personnes (habituellement via un réseau) et de conserver la trace de qui a apporté quelles modifications, les systèmes de gestion de versions font également l'affaire. En fait, c'est pour ces raisons que les systèmes de gestion de versions tels que Subversion sont souvent utilisés dans des environnements de développement logiciel ; travailler au sein d'une équipe de développement est par nature une activité sociale où les modifications au code source sont constamment discutées, réalisées, évaluées et parfois retirées. Les outils de gestion de versions rendent très facile ce type de collaboration.
Bien sûr il existe aussi un coût lié à l'utilisation de la gestion de versions. À moins de pouvoir externaliser l'administration du système de gestion de versions, vous devrez évidemment en assumer l'administration système. En travaillant au jour le jour avec les données, vous ne pourrez pas copier, déplacer, renommer ou supprimer des fichiers de la façon dont vous le faisiez auparavant. À la place, vous devrez accomplir ces tâches via Subversion.
En supposant que cette quantité de travail supplémentaire ne vous pose pas de problème, vous devriez quand même vérifier que vous n'allez pas utiliser Subversion pour résoudre un problème que d'autres outils pourraient résoudre de manière bien plus efficace. Par exemple, parce que Subversion fournit une copie des données à tous les utilisateurs concernés, une erreur courante est de le traiter comme un système de distribution générique. Les gens utilisent parfois Subversion pour partager d'immenses collections de photos, de musique numérique ou de packs logiciels. Le problème est que ce type de donnée ne change en général jamais. La collection grandit au fil du temps, mais les fichiers individuels à l'intérieur de la collection ne changent pas. Dans ce cas, utiliser Subversion est « disproportionné ». [2] Il existe des outils plus simples, capables de copier des données efficacement sans s'embarrasser de toute la gestion du suivi des modifications, tels que rsync ou unison.
Une fois que vous avez décidé d'utiliser un système de gestion de versions, vous aurez pléthore de choix. Au moment où la première version de Subversion a été conçue et est sortie, la version prédominante de la gestion de versions était la gestion centralisée de versions— un serveur maître distant hébergeait les données suivies en versions et les utilisateurs travaillaient localement avec des copies dont l'historique était restreint. Subversion s'est rapidement imposé lors de sa sortie comme le leader incontesté de ce paradigme, étant largement adopté et remplaçant de nombreux systèmes de conception plus anciennes. Il conserve toujours cette position de leader aujourd'hui.
Beaucoup de choses ont changé depuis ce temps. Dans les années qui ont suivi la sortie de Subversion, un nouveau concept de gestion de versions, appelé gestion de versions distribuée (DVCS en anglais, pour distributed version control system), a également suscité beaucoup d'intérêt et a largement été adopté. Des outils tels que Git (https://git-scm.com/) et Mercurial (https://www.mercurial-scm.org/) se sont imposés dans ce créneau des DVCS. Les systèmes de gestion de versions distribués tirent parti du haut débit disponible pour les accès au réseau et du faible coût de stockage pour offrir une approche différente du modèle centralisé de gestion de versions. D'abord, et ce qui est le plus évident, c'est qu'il n'y a plus de serveur central hébergeant seul les données suivies en versions. Chaque utilisateur conserve dans, et travaille sur, des dépôts locaux l'historique (complet dans un sens) des données suivies en versions. Le travail collaboratif a toujours lieu, mais s'accomplit par l'échange direct entre utilisateurs d'ensembles de modifications faites à chacun des éléments suivis en versions, sans passer par un serveur central maître. En fait, toute déclaration de données « maîtres » d'un projet suivi en versions est une pure convention, adoptée par les différents collaborateurs à ce projet.
il existe des avantages et des inconvénients à chacune des approches. Les deux principaux bénéfices que l'on peut tirer des outils décentralisés sont les incroyables performances des opérations quotidiennes (parce que le dépôt des données est stocké localement) et une meilleure gestion des fusions entre branches (parce que les algorithmes de fusion sont ceux qui constituent le cœur même de ce type de logiciel). La contrepartie est que ces systèmes possèdent de manière inhérente un modèle de gestion plus compliqué, qui peut constituer un frein certain au travail collaboratif. Par ailleurs, les DVCS font bien leur travail en partie grâce au contrôle délégué à l'utilisateur, alors que les systèmes centralisés prennent ce contrôle à leur compte — la possibilité de gérer les accès en fonction du chemin dans l'arborescence, la flexibilité pour mettre à jour ou recouvrer individuellement des éléments suivis en versions, etc. Heureusement, beaucoup de grandes organisations ont convenu que le débat n'avait pas à être dogmatique et que Subversion ainsi que les DVCS tels que Git peuvent être utilisés harmonieusement ensemble dans l'organisation, chacun étant utilisé dans l'environnement qui lui convient le mieux.
Hélas, ce livre traite de Subversion, donc nous ne tenterons pas de mener une comparaison exhaustive de Subversion avec les autres outils. Le lecteur à qui il revient de choisir un système de gestion de versions est encouragé à s'enquérir de toutes les options qui s'offrent à lui et à choisir l'outil qui convient le mieux, à lui et à ses collaborateurs. Et si c'est Subversion qui a retenu ses faveurs, ce livre fournit, dans les chapitres qui suivent, des myriades d'informations détaillées pour conduire avec succès la mise en œuvre de Subversion !
Au début des années 2000, CollabNet, Inc. (maintenant connue sous le nom de Digital.ai, https://digital.ai) commença à rechercher des développeurs pour écrire un remplaçant à CVS. CollabNet fournissait [3] une suite logicielle collaborative appelée « CollabNet Enterprise Edition (CEE) » dont l'un des composants est la gestion de versions. Même si CEE utilisait CVS comme système de gestion de versions initial, les limitations de celui-ci étaient évidentes depuis le début, et CollabNet savait qu'il lui faudrait au final trouver quelque chose de mieux. Malheureusement, CVS était devenu le standard de fait dans le monde du logiciel libre, essentiellement parce qu'il n'y avait rien de mieux, en tout cas sous licence libre. Donc CollabNet décida d'écrire un nouveau système de gestion de versions ex nihilo, en conservant les idées de base de CVS, mais sans ses bogues ni ses limitations fonctionnelles.
En février 2000, CollabNet contacta Karl Fogel, l'auteur de Open Source Development with CVS (Coriolis, 1999), et lui demanda s'il aimerait travailler sur ce nouveau projet. Il se trouve qu'au même moment Karl ébauchait la conception d'un nouveau système de gestion de versions avec son ami Jim Blandy. En 1995, ils avaient créé ensemble Cyclic Software, une société fournissant des contrats de support pour CVS, et bien qu'ils aient plus tard revendu la société, ils utilisaient toujours CVS quotidiennement dans leur travail. Leurs frustrations à propos de CVS avaient conduit Jim à élaborer mentalement de meilleures façons de gérer les données suivies en versions. Il avait déjà non seulement trouvé le nom de « Subversion », mais aussi les principes de base du stockage de données de Subversion. Quand CollabNet les appela, Karl accepta immédiatement de travailler sur le projet et Jim obtint de son employeur, Red Hat Software, qu'il le délègue au projet pour une durée indéterminée. CollabNet embaucha Karl et Ben Collins-Sussman, et le travail de conception détaillée commença en mai. Grâce à des coups de pouce efficaces de Brian Behlendorf et Jason Robbins de CollabNet, et de Greg Stein (qui travaillait alors en tant que développeur indépendant, et participait aux spécifications du projet WebDAV/DeltaV), Subversion attira rapidement une communauté de développeurs actifs. Il s'avéra que beaucoup d'entre eux avaient ressenti les mêmes frustrations avec CVS et ils saisirent l'opportunité de pouvoir enfin y faire quelque chose.
L'équipe d'origine se mit d'accord sur quelques objectifs simples. Ils ne voulaient pas inventer de nouvelles méthodes de gestion de versions, ils voulaient juste corriger ce qui n'allait pas dans CVS. Ils décidèrent que Subversion reprendrait les fonctionnalités de CVS et préserverait son modèle de développement, mais ne reproduirait pas ses faiblesses les plus évidentes. Malgré le fait que Subversion devait pouvoir avoir ses propres spécificités, il devait être suffisamment semblable à CVS pour que n'importe lequel de ses utilisateurs puisse facilement passer à Subversion.
Le 31 août 2001, après 14 mois de codage, Subversion devint « auto-hébergeant ». Ce qui veut dire que les développeurs de Subversion cessèrent d'utiliser CVS pour gérer le propre code source de Subversion et commencèrent à utiliser Subversion à la place.
Bien que CollabNet ait initié le projet et qu'elle subventionne encore une grosse partie du travail (en payant les salaires complets de quelques développeurs de Subversion), Subversion fonctionne comme la plupart des projets de logiciel libre, dirigé par un ensemble de règles vagues et transparentes qui encouragent la méritocratie. En 2009, Collabnet a travaillé avec les développeurs de Subversion pour intégrer le projet dans la Apache Software Foundation (ASF), un des regroupement les plus mondialement connus de projets de logiciels libres. Les racines techniques de Subversion, les priorités de sa communauté et les pratiques de développement collaient parfaitement aux de l'ASF, dont beaucoup de membres étaient déjà des contributeurs actifs à Subversion. Début 2010, Subversion a été complètement adopté par la famille des projets phares de l'ASF, a déplacé son point d'ancrage sur le Web vers https://subversion.apache.org et a été rebaptisé « Apache Subversion ».
La Figure 1, « L'architecture de Subversion » donne une « vue d'ensemble » du schéma de conception de Subversion.
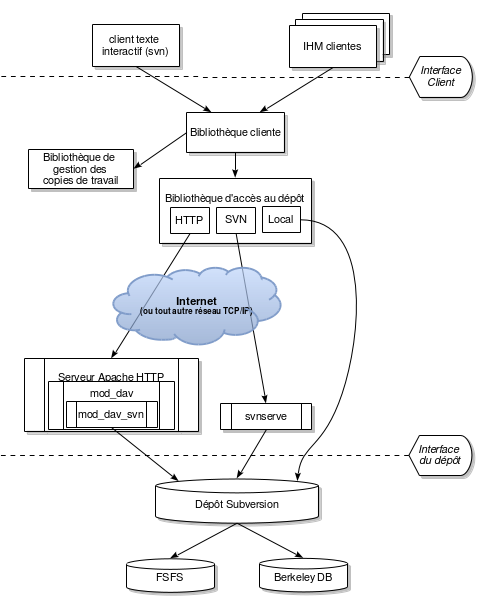
D'un côté, nous avons un dépôt Subversion qui contient toutes vos données suivies en versions. De l'autre côté, il y a votre programme client Subversion, qui gère des versions locales d'une partie de ces données suivies en versions. Entre ces deux extrêmes, il y a des chemins variés utilisant différentes couches d'accès au dépôt. Certains de ces chemins passent par des réseaux informatiques et des serveurs réseau avant d'atteindre le dépôt. D'autres court-circuitent complètement le réseau et accèdent directement au dépôt.
Une fois installé, Subversion est constitué de nombreux composants. Ce qui suit est un survol rapide de ce que vous obtenez. Ne vous inquiétez pas si certaines de ces brèves descriptions vous laissent dubitatif ; ce livre contient de nombreuses pages destinées à dissiper toute confusion.
- svn
-
Le programme client texte interactif.
- svnversion
-
Un programme permettant d'examiner l'état d'une copie de travail (en termes de révisions des éléments présents).
- svnlook
-
Un outil qui permet d'examiner directement un dépôt Subversion.
- svnadmin
-
Un outil destiné à la création, la modification ou la réparation d'un dépôt Subversion.
- mod_dav_svn
-
Un greffon pour le serveur HTTP Apache, utilisé pour rendre votre dépôt disponible à d'autres personnes à travers un réseau.
- svnserve
-
Un serveur autonome créé sur mesure pour Subversion, pouvant fonctionner comme un processus démon ou pouvant être invoqué par SSH ; une autre façon de rendre votre dépôt accessible à d'autres personnes à travers un réseau.
- svndumpfilter
-
Un programme qui permet de filtrer les flux d'exports de l'historique de vos dépôts.
- svnsync
-
Un programme capable de synchroniser de manière incrémentale un dépôt avec un autre dépôt à travers un réseau.
- svnrdump
-
Un programme destiné à réaliser des exports et des chargements de l'historique d'un dépôt à travers un réseau.
- svnmucc
-
Un programme capable d'effectuer des opérations basées sur les URL sur plusieurs dépôts en une seule opération et sans avoir besoin de passer par des copies de travail.
La première édition de ce livre a été publiée par O'Reilly Media en 2004, peu après que Subversion ait atteint la version 1.0. Depuis, le projet Subversion a régulièrement publié de nouvelles versions majeures du logiciel. Voici un résumé rapide des changements majeurs qui ont eu lieu depuis Subversion 1.0. Cette liste n'est pas exhaustive ; pour tous les détails, merci de vous rendre sur le site web de Subversion à l'adresse https://subversion.apache.org.
- Subversion 1.1 (septembre 2004)
-
En version 1.1 fut introduit FSFS qui permet de stocker le dépôt sous forme de fichiers textes. Bien que les bases Berkeley DB soient toujours très utilisées et supportées par la communauté, FSFS est devenu le choix par défaut pour la création de nouveaux dépôts, grâce à sa prise en main facile et à ses besoins minimes en termes de maintenance. Dans cette version ont également été ajoutées les possibilités de suivre en versions des liens symboliques et de prendre en compte automatiquement des URL, ainsi qu'une interface utilisateur régionalisée.
- Subversion 1.2 (mai 2005)
-
La version 1.2 introduisit la possibilité de créer des verrous sur les fichiers côté serveur, sérialisant ainsi l'accès des propagations à certaines ressources. Bien que Subversion soit toujours fondamentalement un système de gestion de versions à accès simultanés, certains types de fichiers binaires (par exemple des images de synthèse) ne peuvent pas être fusionnés. Le mécanisme de verrouillage répond aux besoins de suivi en versions et de protection de ces données. Avec le verrouillage est également apparue une implémentation complète de l'auto-versionnement WebDAV, permettant aux dépôts Subversion d'être accessibles sous la forme de dossiers partagés sur le réseau. Enfin, Subversion 1.2 commença à utiliser un nouvel algorithme plus rapide de différenciation de données binaires pour compresser et récupérer de vieilles versions de fichiers.
- Subversion 1.3 (décembre 2005)
-
Avec la version 1.3, le serveur svnserve sait contrôler les droits en fonction des chemins, ce qui correspondait à une fonctionnalité existant uniquement à cette époque dans le serveur Apache. Cependant, le serveur Apache bénéficia lui-même de nouvelles fonctionnalités de journalisation et les API de connexion entre Subversion et d'autres langages firent également de grands pas en avant.
- Subversion 1.4 (septembre 2006)
-
En version 1.4 fut introduit un tout nouvel outil, svnsync, permettant la réplication, dans une seule direction, d'un dépôt via le réseau. Des parties importantes des métadonnées des copies de travail changèrent de format afin de ne plus utiliser XML (avec pour conséquence des gains en rapidité côté client), tandis que le gestionnaire de base de données des dépôts Berkeley DB acquit la capacité de rétablir les bases automatiquement suite à un crash du serveur.
- Subversion 1.5 (juin 2008)
-
Sortir la version 1.5 prit beaucoup plus de temps que les autres versions, mais la fonctionnalité vedette était titanesque : le suivi semi-automatisé des branches et des fusions. Ce fut une véritable bénédiction pour les utilisateurs et propulsa Subversion bien au-delà des possibilités de CVS, le plaçant à la hauteur de ses concurrents commerciaux tels que Perforce et Clearcase. En version 1.5 tout un tas d'autres fonctionnalités axées sur l'utilisateur furent introduites, telles que la résolution interactive des conflits entre fichiers, les extractions partielles, la gestion des listes de modifications côté client, une nouvelle syntaxe très puissante pour les définitions externes et le support par le serveur svnserve de l'authentification par SASL.
- Subversion 1.6 (mars 2009)
-
La version 1.6 renforça la gestion des branches et des fusions en introduisant la notion de conflits d'arborescences. Elle améliorait également plusieurs fonctionnalités déjà existantes : davantage d'options pour la résolution interactive des conflits, support d'exclusions pour les extractions partielles, définitions externes à partir de fichiers, journalisation opérationnelle pour la commande svnserve similaire à celle fournie par mod_dav_svn. Par ailleurs, le client texte interactif introduisit de nouveaux raccourcis pour référencer les URL de dépôts Subversion.
- Subversion 1.7 (octobre 2011)
-
La version 1.7 constituait en premier lieu un moyen de livrer deux grosses évolutions à des composants un peu vieillissants de Subversion. Celle ayant le plus d'impact s'appelait « WC-NG » ; une réécriture complète de la bibliothèque libsvn_wc de gestion des copies de travail. La deuxième évolution était l'introduction d'un protocole HTTP plus léger pour l'interaction entre le client et le serveur Subversion. Subversion 1.7 offrait une poignée de nouvelles fonctionnalités, beaucoup de résolutions de bugs et aussi quelques notables améliorations de performances.
- Subversion 1.8 (juin 2013)
-
Dans la version 1.8, le client Subversion améliore le suivi des renommages de fichiers et de répertoires ; la commande svn merge a suffisamment muri pour rendre l'utilisation de l'option
--reintegrateinutile. Certaines nouvelles valeurs de propriétés suivies en versions peuvent être héritées des dossiers parents. Cette fonctionnalité permet maintenant de fixer des valeurs par défaut pour la définition des propriétés automatiques et les motifs de noms de fichiers à ignorer, ce qui apporte de la cohérence pour tous les utilisateurs d'un dépôt alors que, auparavant, cela devait se gérer de manière collaborative. Il intègre aussi un nouvel outil de fusion en ligne de commande pour la résolution interactive des conflits. Et comme toujours, Subversion 1.8 inclut beaucoup de fonctionnalités supplémentaires, la résolution de bugs et des améliorations dans le comportement et les performances.
