La misión principal de un sistema de control de versiones es permitir la edición colaborativa y la compartición de los datos. Sin embargo, existen diferentes sistemas que utilizan diferentes estrategias para alcanzar este objetivo.
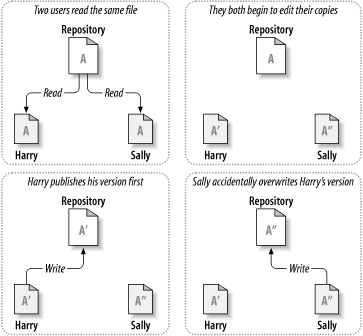
Todos los sistemas de control de versiones tienen que resolver un problema fundamental: ¿Cómo permitirá el sistema a los usuarios el compartir información, pero al mismo tiempo impedirá que se pisen los callos mutuamente de forma accidental? Es muy sencillo para los usuarios el sobreescribir accidentalmente los cambios de los demás en el repositorio.
Considere el escenario mostrado en Figura 2.2, “El problema a evitar”. Suponga que tenemos dos colaboradores, Juan y Carmen. Cada uno de ellos decide editar el mismo archivo del repositorio al mismo tiempo. Si Juan guarda sus cambios en el repositorio en primer lugar, es posible que (unos momentos más tarde) Carmen los sobreescriba accidentalmente con su propia versión del archivo. Si bien es cierto que la versión de Juan no se ha perdido para siempre (porque el sistema recuerda cada cambio), cualquier cambio que Juan haya hecho no estará presente en la versión más reciente de Carmen porque, para empezar, ella nunca vio los cambios de Juan. El trabajo de Juan sigue efectivamente perdido—o al menos ausente en la última versión del archivo—y probablemente por accidente. ¡Esta es definitivamente una situación que queremos evitar!
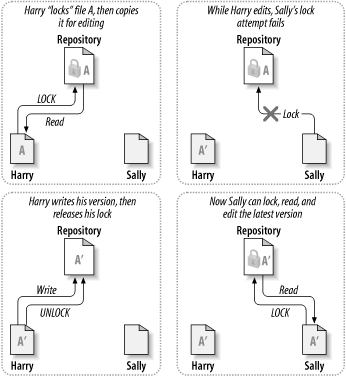
Muchos sistemas de control de versiones utilizan un modelo de bloqueo-modificación-desbloqueo para atacar este problema. En un sistema como éste, el repositorio sólo permite a una persona modificar un archivo al mismo tiempo. Juan debe “bloquear” primero el archivo para luego empezar a hacerle cambios. Bloquear un archivo se parece mucho a pedir prestado un libro de la biblioteca; si Juan ha bloqueado el archivo, entonces Carmen no puede hacerle cambios. Por consiguiente, si ella intenta bloquear el archivo, el repositorio rechazará la petición. Todo lo que puede hacer es leer el archivo y esperar a que Juan termine sus cambios y deshaga el bloqueo. Tras desbloquear Juan el archivo, Carmen puede aprovechar su turno bloqueando y editando el archivo. La figura Figura 2.3, “La solución bloqueo-modificación-desbloqueo” demuestra esta sencilla solución.
El problema con el modelo bloqueo-modificación-desbloqueo es que es un tanto restrictivo y a menudo se convierte en un obstáculo para los usuarios:
-
Bloquear puede causar problemas administrativos. En ocasiones Juan bloqueará un archivo y se olvidará de él. Mientras tanto, como Carmen está aún esperando para editar el archivo, sus manos están atadas. Y luego Juan se va de vacaciones. Ahora Carmen debe conseguir que un administrador deshaga el bloqueo de Juan. La situación termina causando muchas demoras innecesarias y pérdida de tiempo.
-
Bloquear puede causar una serialización innecesaria. ¿Qué sucede si Juan está editando el inicio de un archivo de texto y Carmen simplemente quiere editar el final del mismo archivo? Estos cambios no se solapan en absoluto. Ambos podrían editar el archivo simultáneamente sin grandes perjuicios, suponiendo que los cambios se combinaran correctamente. No hay necesidad de turnarse en esta situación.
-
Bloquear puede causar una falsa sensación de seguridad. Imaginemos que Juan bloquea y edita el archivo A, mientras que Carmen bloquea y edita el archivo B al mismo tiempo. Pero suponga que A y B dependen uno del otro y que los cambios hechos a cada uno de ellos son semánticamente incompatibles. Súbitamente A y B ya no funcionan juntos. El sistema de bloqueo se mostró ineficaz a la hora de evitar el problema—sin embargo, y de algún modo, ofreció una falsa sensación de seguridad. Es fácil para Juan y Carmen imaginar que al bloquear archivos, cada uno está empezando una tarea segura y aislada, lo cual les inhibe de discutir sus cambios incompatibles desde un principio.
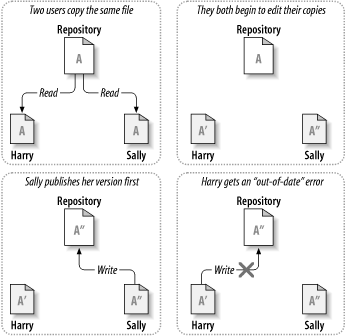
Subversion, CVS y otros sistemas de control de versiones utilizan un modelo del tipo copiar-modificar-mezclar como alternativa al bloqueo. En este modelo, el cliente de cada usuario se conecta al repositorio del proyecto y crea una copia de trabajo personal—una réplica local de los archivos y directorios del repositorio. Los usuarios pueden entonces trabajar en paralelo, modificando sus copias privadas. Finalmente, todas las copias privadas se combinan (o mezclan) en una nueva versión final. El sistema de control de versiones a menudo ayuda con la mezcla, pero en última instancia es un ser humano el responsable de hacer que ésto suceda correctamente.
He aquí un ejemplo. Digamos que Juan y Carmen crean sendas copias de trabajo del mismo proyecto, extraídas del repositorio. Ambos trabajan concurrentemente y hacen cambios a un mismo archivo A dentro de sus copias. Carmen guarda sus cambios en el repositorio primero. Cuando Juan intenta guardar sus cambios más tarde, el repositorio le informa de que su archivo A está desactualizado. En otras palabras, que el archivo A en el repositorio ha sufrido algún cambio desde que lo copió por última vez. Por tanto, Juan le pide a su cliente que mezcle cualquier cambio nuevo del repositorio con su copia de trabajo del archivo A. Es probable que los cambios de Carmen no se solapen con los suyos; así que una vez que tiene ambos juegos de cambios integrados, Juan guarda su copia de trabajo de nuevo en el repositorio. Las figuras Figura 2.4, “La solución copiar-modificar-mezclar” y Figura 2.5, “La solución copiar-modificar-mezclar (continuación)” muestran este proceso.
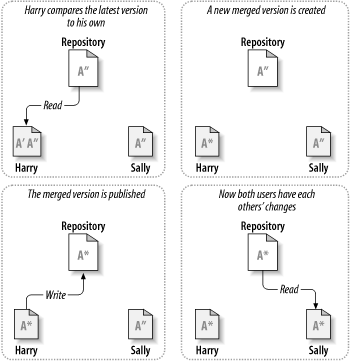
¿Pero qué ocurre si los cambios de Carmen sí se solapan con los de Juan? ¿Entonces qué? Esta situación se conoce como conflicto y no suele suponer un gran problema. Cuando Juan le pide a su cliente que mezcle los últimos cambios del repositorio en su copia de trabajo, su copia del archivo A se marca de algún modo para indicar que está en estado de conflicto: Juan podrá ver ambos conjuntos de cambios conflictivos y escoger manualmente entre ellos. Observe que el programa no puede resolver automáticamente los conflictos; sólo los humanos son capaces de entender y tomar las decisiones inteligentes oportunas. Una vez que Juan ha resuelto manualmente los cambios solapados—posiblemente después de discutirlos con Carmen—ya podrá guardar con seguridad el archivo mezclado en el repositorio.
La solución copiar-modificar-mezclar puede sonar un tanto caótica, pero en la práctica funciona extremadamente bien. Los usuarios pueden trabajar en paralelo, sin tener que esperarse el uno al otro. Cuando trabajan en los mismos archivos, sucede que la mayoría de sus cambios concurrentes no se solapan en absoluto; los conflictos son poco frecuentes. El tiempo que toma resolver los conflictos es mucho menor que el tiempo perdido por un sistema de bloqueos.
Al final, todo desemboca en un factor crítico: la comunicación entre los usuarios. Cuando los usuarios se comunican pobremente, los conflictos tanto sintácticos como semánticos aumentan. Ningún sistema puede forzar a los usuarios a comunicarse perfectamente, y ningún sistema puede detectar conflictos semánticos. Por consiguiente, no tiene sentido dejarse adormecer por la falsa promesa de que un sistema de bloqueos evitará de algún modo los conflictos; en la práctica, el bloqueo parece inhibir la productividad más que otra cosa.