版本控制系统用于跟踪文件和目录在时间上的增量版本. 当然, 仅仅跟踪一 个用户或用户组不同版本的文件和目录并不会让版本控制系统显得多么高级, 它的真正用处是允许用户查看每个版本所发生的变化, 对任意一个修改进行 撤消.
本节将介绍一些版本控制系统比较高层的组成部分和概念, 内容只限于 现代的版本控制系统—在如今这个时代, 如果一个版本控制系统无法在 广域网下工作, 估计没多少人愿意使用它.
版本控制系统的核心是仓库, 它是存放系统数据的中央位置. 仓库通常以 文件系统树 (filesystem tree ) 的形式存放信息, 文件系统树是文件和目录的分层结构. 有任意数量的 客户端 (client) 连接到仓库, 对其中的文件进行读写 访问. 通过向仓库写数据, 客户端将信息暴露给其他人; 通过读取数据, 客户端获得了其他人的信息, 如 图 1.1 “典型的客户端/服务器系统” 所示:
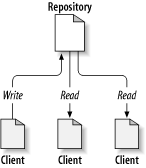
为什么这很重要? 目前来看, 仓库像是一个典型的文件服务器. 确实是, 但是它和你平时用的文件服务器并不完全相同, 仓库的独特之处是随着文件 不断地发生变化, 它会记住文件的每一个版本.
当客户端从仓库读取数据时, 它通常只会读取到文件系统树的最新版本, 但是版本控制系统客户端的一个重要功能是它也可以读到早先版本的文件 系统树. 版本控制系统客户端可以询问历史问题, 例如 “在上周三时, 这个目录中存放的是什么内容?” 和 “修改这个文件的最后 一个人是谁? 他改了什么?” 这些是任意一个版本控制系统都 要有能力解决的问题.
版本控制系统的核心价值在于它可以跟踪文件和目录的版本, 但是其他 软件不会操作 “文件和目录的版本”, 大多数软件只能理解 如何操作某种特定类型文件的 单一 版本, 那么用户 如何才能以一种实实在在的方式, 和一个包含了不同文件多个版本的, 抽象的, 远程的仓库进行交互? 用户的字处理软件, 演示软件, 源代码编辑器, 网页设计软件—以及其他一些只能处理单一版本文件的程序— 如何才能访问仓库中的文件? 答案是 工作副本 (working copy).
顾名思义, 工作副本是仓库的特定版本数据在本地的副本, 用户可以 自由地对它进行操作. 对其他软件来说, 工作副本[5] 只是一个普通的本地目录, 所以即使它们不具备版本控制功能也可以对 工作副本进行读写. 版本控制系统的客户端工具负责管理工作副本, 以及 与仓库通信.
如果说版本控制系统的首要工作是跟踪文件和目录在时间上的不同版本, 那么它的次要工作就是支持协作编辑和数据共享. 不同的版本控制系统在实现 后者时可能会采用不同的策略, 理解这些策略的差别非常重要, 这主要基于以 下两点考虑: 首先, 这可以帮助你比较不同的版本控制系统, 特别是在你遇到 了一个和 Subversion 相似的系统; 然后, 这可以帮助你更高效地使用 Subversion, 因为 Subversion 支持多种不同的工作模式.
所有的版本控制系统都要解决一个基本问题: 如何允许用户共享信息, 同时避免他们无意之间互相干扰? 一个用户无意间覆盖了其他用户的修改 —这种情况经常发生.
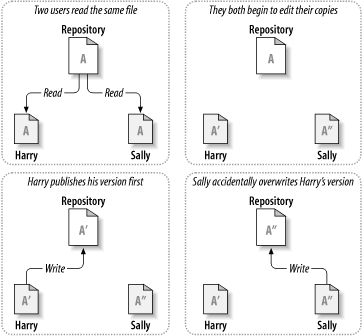
考虑 图 1.2 “需要避免的情况” 所示的情境. 假设现在有两个同事, Harry 和 Sally, 他们在同一时间修改 了仓库中的同一文件. 如果 Harry 先把修改保存到仓库中, 后面 Sally 就有可能用他的新版本文件覆盖掉 Harry 的版本. 虽然 Harry 的修改 不会就此丢失 (因为版本控制系统会记住每一次修改), 但是 Harry 的修改 不会出现在 Sally 的新版本文件中, 因为他从未看到过 Harry 的修改. 从效果上来看, Harry 的修改丢失了—至少是对文件的最新版本来说 —而且很有可能是无意间导致的, 我们决不能让这种情况发生.
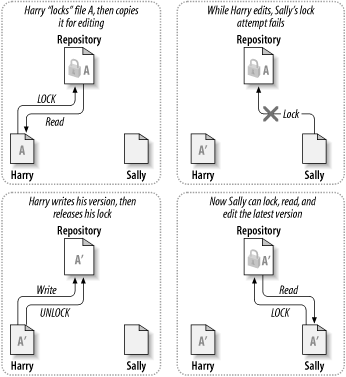
为了解决用户间互相干扰工作的问题, 许多版本控制系统都采用了 加锁-修改-解锁 (lock-modify-unlock) 模型. 在这个模型中, 仓库一次只允许一个用户修改同一文件, 这种独占策略通过锁进行管理. Harry 在修改之前要先对文件进行 “加锁” (lock), 如果 Harry 已经锁住了文件, Sally 就不能再对同一文件进行加锁, 也就不能 修改文件. 他所能做的就是等待 Harry 完成修改, 保存文件, 然后释放 锁. Harry 解锁后才能轮到 Sally 加锁, 然后他可能会得到一个新版本的 文件并开始编辑. 图 1.3 “加锁-修改-解锁 解决方案” 展示了 工作流程.
加锁-修改-解锁 模型的问题是限制比较多, 经常会成为用户的麻烦:
-
加锁可能会导致管理上的问题. 有时候 Harry 在锁住一个文件后可能会忘了给它解锁, 同时 Sally 还在焦急地等着. 如果 Harry 去度假了, 那么 Sally 必须找到 仓库管理员, 让他释放 Harry 的锁. 这种情况会浪费大量的时间.
-
加锁可能会导致不必要的串行化. 如果 Harry 想要修改文件的开头部分, 而 Sally 只想修改同一文件 的结尾部分? 此时他们的修改就不会重叠. 如果他们的修改可以恰当 地合并在一起, 那他们就可以同时编辑文件, 完全不会产生任何问题. 此时对文件进行加锁就完全没有必要.
-
加锁可能会造成安全上的错觉. 假设 Harry 加锁并修改了文件 A, 同时 Sally 加锁并修改了文件 B, 文件 A 和文件 B 在内容是互相依赖的, 如果 Harry 和 Sally 的 修改在语义上是不兼容的, 那将会如何? 文件 A 和文件 B 可能无法 再正常工作. 加锁-修改-解锁 模型对这种情况无能为力—但是用 户会错误地认为只要在加锁后修改就是安全的. 通过加锁, Harry 和 Sally 都错误地认为自己的修改是安全的, 也就不会事先和对方沟通. 锁机制常常会代替真正的交流.
Subversion, CVS 和许多其他的版本控制系统使用 复制-修改-合并 (copy-modify-merge ) 模型作为锁机制的替代品. 在这个模型中, 每一个用户的 客户端都与仓库通信, 在本地创建一份私有的工作副本, 然后用户可以同时 地, 互不干扰地修改自己的私有副本, 最后, 私有副本被合并到一个新的 最终版本. 为了支持 复制-修改-合并 模型, 版本控制系统通常会提供合并 操作, 但是归根到底, 必须由用户自己来确保合并的结果是正确的.
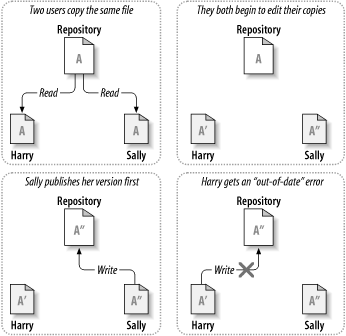
我们通过例子来说明. 假设 Harry 和 Sally 各自创建了同一项目 的工作副本, 并在各自的工作副本中修改了同一文件 A. Sally 先把 修改保存到仓库中, 后面 Harry 试图保存自己的修改时, 仓库告诉他 文件 A 已经 过时 (out of date ) 了, 换句话说, 自从他上一次复制了文件 A 之后, 仓库中 的文件 A 被更新了. 于是, Harry 告诉客户端把仓库中文件 A 的更新合 并到他的工作副本中 (这里不妨假设 Sally 的修改没有和他的修改重叠), 修改合并后, Harry 再一次向仓库保存了他自己的修改. 图 1.4 “复制-修改-合并 解决方案” 和 图 1.5 “复制-修改-合并 解决方案 (续)” 展示了 工作流程.
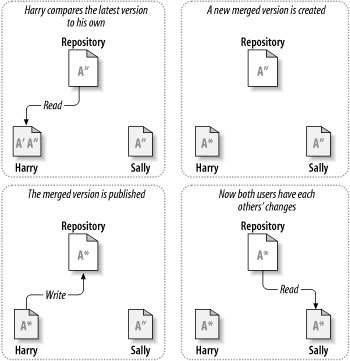
但是如果 Sally 的修改和 Harry 重叠了, 那又会产生什么结果? 这种情况称为 冲突 (conflict), 通常不是什么大问题. 当 Harry 告诉客户端把仓库的最新修改合并到他的工作副本时, 副本中的文件 A 被标记为冲突状态: Harry 可以同时看到互相冲突的两套修改, 并对它们 进行手工选择. 软件不会自动地解决冲突, 只有人类才能理解冲突并做出 正确地选择. Harry 把重叠的修改解决后—可能是在和 Sally 沟通 之后—就可以把合并后的文件安全地保存到仓库中.
复制-修改-合并 模型看起来好像有点混乱, 但是在实际使用中它 运行地很流畅. 用户可以并发地工作, 不用等待其他人, 当用户操作 同一文件时, 经验表明他们的大多数修改不会重叠, 冲突情况其实很少发 生. 解决冲突花费的时间通常要比使用锁机制浪费的时间要少得多.
上面所说的问题都涉及到一个关键因素: 用户间的沟通. 如果用户间 缺乏沟通, 发生语法冲突和语义冲突的概率都会增加. 没有一个版本控制 系统可以强制用户沟通或检测语义冲突, 所以不要认为使用锁机制可以完 全避免产生冲突, 在实际使用中, 锁机制似乎会影响工作效率.
