Un système de gestion de versions (ou de contrôle de versions) est un système qui garde une trace de toutes les versions (ou révisions) des fichiers et, dans certains cas, des répertoires au cours du temps. Bien sûr, simplement garder la trace de toutes les modifications apportées par un utilisateur (ou un groupe d'utilisateurs) à des fichiers et des répertoires n'est pas intéressant en tant que tel. Ce qui définit l'utilité d'un système de gestion de versions est la possibilité d'examiner les modifications apportées par chaque changement et de faciliter le retour vers n'importe quelle version.
Dans cette section, nous allons introduire des notions et des outils de haut-niveau pour la gestion de versions. Nous limiterons notre exposé aux systèmes modernes de gestions de versions— dans notre monde connecté actuel, il est de peu d'intérêt de s'attarder sur les systèmes qui ne peuvent pas fonctionner au travers des grands réseaux.
Le dépôt constitue le cœur d'un système de gestion de versions ; c'est le lieu de stockage central des données gérées. Généralement, les informations y sont organisées sous la forme d'une arborescence de fichiers, c'est-à-dire une hiérarchie classique de fichiers et de répertoires. Un certain nombre de clients se connectent au dépôt, et parcourent ou modifient ces fichiers. En modifiant des données, un client rend ces informations disponibles aux autres clients ; en lisant des données, le client reçoit des informations des autres clients. La Figure 1.1, « Un authentique système client/serveur » illustre cela.

Quel est l'intérêt ? Jusque-là, cela ressemble à la définition d'un serveur de fichiers classique. En fait, le dépôt est bien une sorte de serveur de fichiers, mais d'un type particulier. Ce qui rend le dépôt spécial, c'est qu'il se souvient de toutes les versions de chacun des fichiers.
Quand un client parcourt le dépôt, il consulte généralement la dernière version de l'arborescence du système de fichiers. Mais, et c'est là l'intérêt d'un système de gestion de versions, le client est également capable de demander au dépôt les états antérieurs du système de fichiers. Par exemple, un client peut poser des questions concernant l'historique des données, comme « Que contenait ce répertoire mercredi dernier ? » ou « Quelle est la dernière personne qui a modifié ce fichier, et quels changements a-t-elle effectués ? ». C'est le genre de questions qui est au cœur de tout logiciel de gestion de versions.
La plus-value d'un système de gestion de versions provient de sa capacité à garder une trace de toutes les versions des fichiers et répertoires, mais les autres logiciels n'intègrent pas cette notion de « versions de fichiers et répertoires ». La plupart des logiciels ne savent manipuler qu'une seule version d'un type de fichier. Alors, comment l'utilisateur du système de gestion de versions interagit-il concrètement avec un dépôt abstrait — et souvent distant — plein de multiples versions des différents fichiers ? Comment son traitement de textes, son logiciel de présentation, son éditeur de code source ou de site web, ou n'importe quel autre logiciel peut-il avoir accès à ces fichiers suivis en versions ? La réponse se trouve dans ce que la gestion de versions appelle la copie de travail.
Une copie de travail est, littéralement, une copie locale d'une version particulière des données gérées en versions par l'utilisateur, sur laquelle il est libre de travailler. Les copies de travail[5] sont vus par les autres logiciels comme n'importe quel autre répertoire rempli de fichiers, ainsi ces programmes n'ont pas besoin d'être « conscients » de la gestion de versions pour lire ou écrire des données dans ces fichiers. C'est le rôle du logiciel de gestion de versions de prendre en compte et communiquer les modifications du contenu de la copie de travail ou du dépôt.
Si la mission première d'un logiciel de gestion de versions est de tracer l'historique des différentes versions dans le temps des données numériques, une seconde mission concomitante dans n'importe quel gestionnaire de versions moderne consiste à permettre l'édition collaborative et le partage de ces données. Mais il existe différentes stratégies pour arriver à cette fin. Comprendre ces différentes stratégies est important à plusieurs titres. Tout d'abord, cela vous aidera à comparer et différencier les logiciels de gestion de versions existants, au cas où vous rencontriez d'autres logiciels similaires à Subversion. Ensuite, cela vous aidera également à utiliser plus efficacement Subversion, puisque Subversion lui-même autorise différentes façons de travailler.
Tous les logiciels de gestion de versions doivent résoudre le même problème fondamental : comment le logiciel va-t-il permettre aux utilisateurs de partager l'information, tout en les empêchant de se marcher mutuellement sur les pieds par accident ? Il est vraiment trop facile pour les utilisateurs d'écraser malencontreusement les changements effectués par d'autres dans le dépôt.
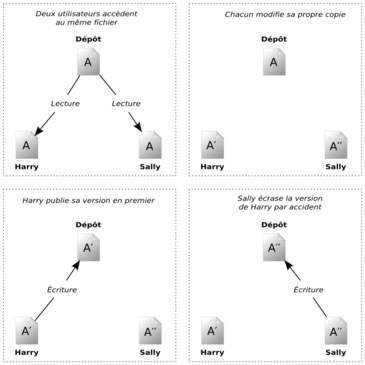
Observons le scénario décrit à la Figure 1.2, « La situation à éviter ». Supposons que nous ayons deux collaborateurs, Harry et Sally. Ils décident tous les deux d'éditer au même moment le même fichier dans le dépôt. Si Harry sauvegarde ses modifications dans le dépôt en premier, il est possible que, quelques instants plus tard, Sally les écrase avec sa propre version du fichier. Bien que la version de Harry ne soit pas perdue pour toujours, car le système se souvient de tous les changements, aucune des modifications effectuées par Harry n'est présente dans la nouvelle version du fichier de Sally, car elle n'a jamais vu les changements réalisés par Harry. De fait, le travail de Harry est perdu ou, du moins, perdu dans la version finale du fichier, et ceci probablement par accident. Il s'agit précisément d'une situation que nous voulons à tout prix éviter !
De nombreux logiciels de gestion de versions utilisent le modèle verrouiller-modifier-libérer pour résoudre le problème de plusieurs auteurs annihilant le travail des autres. Dans ce modèle, le dépôt ne permet qu'à une seule personne de modifier un fichier à un instant donné. Cette politique exclusive est gérée grâce à des verrous (lock en anglais). Harry doit « verrouiller » un fichier avant de commencer à le modifier. Si Harry a verrouillé un fichier, alors Sally ne peut pas le verrouiller et ne peut donc faire aucun changement dessus. Tout ce qu'elle peut faire, c'est lire le fichier et attendre que Harry ait fini ses changements puis libéré le verrou. Après que Harry ait libéré le fichier, Sally pourra à son tour le verrouiller et l'éditer. La Figure 1.3, « Modèle verrouiller-modifier-libérer » illustre cette solution très simple.
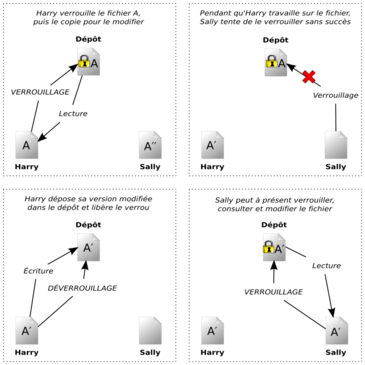
Le problème avec le modèle verrouiller-modifier-libérer est qu'il est relativement restrictif et devient souvent un barrage pour les utilisateurs :
-
Le verrouillage peut créer des problèmes d'administration. Parfois, Harry va verrouiller un fichier et oublier qu'il l'a fait. Pendant ce temps, Sally, qui est encore en train d'attendre pour éditer le fichier, est bloquée. Puis Harry part en vacances. Sally doit alors aller trouver un administrateur pour libérer le verrou de Harry. La situation finit par générer beaucoup de délais inutiles et de temps perdu.
-
Le verrouillage peut créer une sérialisation inutile. Que se passe-t-il lorsque Harry veut éditer le début d'un fichier texte et que Sally veut simplement éditer la fin de ce même fichier ? Ces changements ne se chevauchent pas du tout. Ils pourraient aisément éditer le fichier simultanément et il n'y aurait pas beaucoup de dégâts, en supposant que les changements soient correctement fusionnés. Dans cette situation, il n'est pas nécessaire de les forcer à éditer le fichier chacun à leur tour.
-
Le verrouillage peut créer un faux sentiment de sécurité. Supposons que Harry verrouille et édite le fichier A, alors qu'au même moment Sally verrouille et édite le fichier B. Que se passe-t-il si A et B dépendent l'un de l'autre et que les changements faits à chacun sont incompatibles d'un point de vue sémantique ? A et B ne fonctionnent soudainement plus ensemble. Le système de verrouillage a été incapable d'empêcher ce problème, bien qu'il ait d'une certaine manière instillé un faux sentiment de sécurité. Il est facile pour Harry et Sally d'imaginer qu'en verrouillant les fichiers, chacun commence une tâche isolée, sans danger et donc que ce n'est pas la peine de discuter à l'avance de leurs modifications incompatibles. Verrouiller devient souvent un substitut à une réelle communication.
Subversion, CVS et beaucoup d'autres logiciels de gestion de versions utilisent le modèle copier-modifier-fusionner comme alternative au verrouillage. Dans ce modèle, chaque utilisateur contacte le dépôt du projet via son client et crée une copie de travail personnelle, une sorte de version locale des fichiers et répertoires du dépôt. Les utilisateurs peuvent alors travailler, simultanément et indépendamment les uns des autres, et modifier leurs copies privées. Pour finir, les copies privées sont fusionnées au sein d'une nouvelle version finale. Le logiciel de gestion de versions fournit de l'aide afin de réaliser cette fusion, mais au final la responsabilité de s'assurer que tout se passe bien incombe à un être humain.
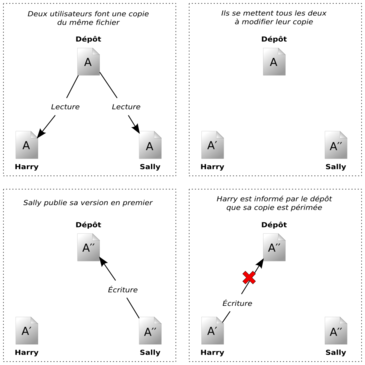
Voici un exemple. Supposons que Harry et Sally aient créé chacun des copies de travail du même projet, copiées à partir du dépôt. Ils travaillent simultanément et effectuent sur leur copie des modifications du même fichier A. Sally sauvegarde ses changements dans le dépôt en premier. Lorsque Harry essaie par la suite de sauvegarder ses modifications, le dépôt l'informe que son fichier A est périmé. En d'autres termes, le fichier A du dépôt a changé, d'une façon ou d'une autre, depuis la dernière fois qu'il l'avait copié. Harry demande donc à son client de fusionner tous les changements en provenance du dépôt dans sa copie de travail du fichier A. Il y a des chances que les modifications de Sally n'empiètent pas sur les siennes ; une fois qu'il a intégré les changements provenant des deux côtés, il sauvegarde sa copie de travail dans le dépôt. La Figure 1.4, « Modèle copier-modifier-fusionner » et la Figure 1.5, « Modèle copier-modifier-fusionner (suite) » illustrent ce processus.
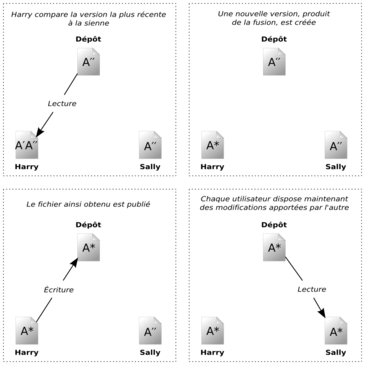
Mais que se passe-t-il quand les modifications de Sally empiètent sur celles de Harry ? Que fait-on dans ce cas-là ? Cette situation est appelée un conflit et ne constitue pas, en général, un gros problème. Lorsque Harry demande à son logiciel client de fusionner les changements les plus récents du dépôt dans sa copie de travail, sa copie du fichier est en quelque sorte marquée comme étant dans un état de conflit : il a la possibilité de voir les deux ensembles de changements entrant en conflit et de choisir manuellement entre les deux. Notez bien qu'un logiciel ne peut pas résoudre automatiquement les conflits ; seuls les humains sont capables de comprendre et de faire les choix intelligents nécessaires. Une fois que Harry a manuellement résolu les modifications se chevauchant, par exemple après une discussion avec Sally, il peut sauvegarder le fichier fusionné en toute sécurité dans le dépôt.
Le modèle copier-modifier-fusionner peut sembler un peu chaotique mais, en pratique, il fonctionne de façon très fluide. Les utilisateurs peuvent travailler en parallèle, sans jamais devoir s'attendre les uns les autres. Lorsqu'ils travaillent sur les mêmes fichiers, il s'avère que la plupart des changements réalisés en parallèle ne se chevauchent pas du tout ; les conflits sont rares. Et le temps nécessaire à la résolution des conflits est en général bien inférieur au temps gaspillé par un système de verrouillage.
Au final, tout revient à un facteur critique : la communication entre les utilisateurs. Lorsque les utilisateurs communiquent mal, les conflits syntaxiques et sémantiques augmentent. Aucun système ne peut forcer les utilisateurs à communiquer parfaitement et aucun système ne peut détecter les conflits sémantiques. Il n'y a donc aucun intérêt à se laisser endormir par un faux sentiment de sécurité selon lequel un système de verrouillage permettrait d'éviter les conflits ; en pratique, le verrouillage semble limiter la productivité plus qu'aucun autre facteur.
[5] Le terme « copie de travail » peut s'appliquer à n'importe quel fichier dans sa version extraite. Cependant, la majeure partie des gens utilise ce terme pour désigner la sous-arborescence complète contenant les fichiers et répertoires gérés par le système de gestion de versions.
