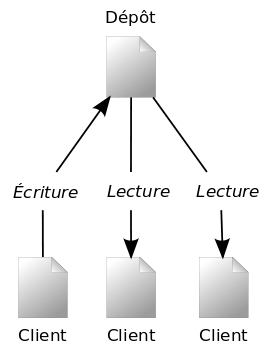
Subversion est un système centralisé fait pour partager l'information. Le dépôt constitue le cœur de ce système, en tant que lieu de stockage central des données. Les informations y sont organisées sous la forme d'une arborescence de fichiers, c'est-à-dire une hiérarchie classique de fichiers et de répertoires. Un certain nombre de clients se connectent au dépôt, et parcourent ou modifient ces fichiers. En modifiant des données, un client rend ces informations disponibles à d'autres personnes ; en lisant des données, le client reçoit les informations des autres personnes. La Figure 1.1, « Un authentique système client/serveur » illustre cela.
Quel est l'intérêt ? Jusque là, cela ressemble à la définition d'un serveur de fichiers classique. En fait, le dépôt est bien une sorte de serveur de fichiers, mais d'un type particulier. Ce qui rend le dépôt Subversion spécial, c'est qu'il se souvient de toutes les modifications qui ont été apportées : chaque modification de chaque fichier, ainsi que les modifications de l'arborescence-même des répertoires, comme l'ajout, la suppression ou la réorganisation de fichiers et de répertoires.
Quand un client parcourt le dépôt, il consulte généralement la dernière version de l'arborescence du système de fichiers. Mais le client est également capable de visualiser des états antérieurs du système de fichiers. Par exemple, un client peut poser des questions concernant l'historique des données, comme « Que contenait ce répertoire mercredi dernier ? » ou « Quelle est la dernière personne qui a modifié ce fichier, et quels changements a-t-elle effectué ? ». C'est le genre de questions qui est au cœur de tout logiciel de gestion de versions, logiciel conçu pour conserver l'historique des modifications des données au cours du temps.