Subversion ist ein freies/Open-Source Versions-Kontroll-System (VCS). Das bedeutet, Subversion verwaltet Dateien und Verzeichnisse und die Änderungen an ihnen im Lauf der Zeit. Das erlaubt Ihnen, alte Versionen Ihrer Daten wiederherzustellen oder die Geschichte der Änderungen zu verfolgen. Unter diesem Blickwinkel denken viele Leute bei einem Versions-Kontroll-System an eine Art „Zeitmaschine“.
Subversion kann netzwerkübergreifend arbeiten, was die Benutzung durch Menschen an verschiedenen Computern ermöglicht. Auf einer bestimmten Ebene fördert die Fähigkeit, unterschiedlicher Personen dieselbe Menge an Daten bearbeiten und verwalten zu können, die Zusammenarbeit. Ohne auf einen einzigen Kanal beschränkt zu sein, über den alle Änderungen abgewickelt werden müssen, kann das Vorankommen beschleunigt werden. Und weil die Arbeit versioniert ist, braucht nicht befürchtet zu werden, dass die Qualität bei Verlust dieses Kanals geopfert wird – falls irgendeine falsche Änderung an den Daten gemacht wird, kann man sie einfach zurücknehmen.
Manche Versions-Kontroll-Systeme sind auch Software-Konfigurationsmanagement-Systeme (SCM). Diese Systeme sind maßgeschneidert, um ganze Verzeichnisbäume mit Quellcode zu verwalten und verfügen über viele Merkmale, die spezifisch für Software-Entwicklung sind – etwa das Verstehen von Programmiersprachen oder das Bereitstellen von Werkzeugen zum Bauen von Software. Jedoch gehört Subversion nicht zu diesen Systemen. Es ist ein allgemeines System, das verwendet werden kann, um alle möglichen Sammlungen von Dateien zu verwalten. Für Sie mag es sich dabei um Quellcode handeln – für andere mag es dabei um alles von Einkaufslisten bis zu digitalen Videomischungen und weit darüber hinaus gehen.
Falls Sie ein Anwender oder Systemadministrator sind und den Einsatz von Subversion erwägen, sollte die erste Frage, die Sie sich stellen, sein: "Ist es das richtige Werkzeug für die Aufgabe?" Subversion ist ein fantastischer Hammer, achten Sie jedoch darauf, dass Sie nicht jedes Problem als einen Nagel sehen.
Zunächst müssen Sie sich entscheiden, ob Versionskontrolle generell für Ihre Zwecke benötigt wird. Falls Sie alte Datei- und Verzeichnisversionen aufbewahren, sie eventuell wiedererwecken müssen, und Protokolle darüber auswerten möchten, wie sie sich im Lauf der Zeit geändert haben, dann können das Versions-Kontroll-Werkzeuge bewerkstelligen. Wenn Sie mit mehreren Leuten gemeinsam (üblicherweise über das Netz) an Dokumenten arbeiten und verfolgen müssen, wer welche Änderung gemacht hat, dann kann ein Versions-Kontroll-Werkzeug auch das. Deshalb werden Versions-Kontroll-Werkzeuge wie Subversion so oft in Software-Entwicklungs-Umgebungen eingesetzt – die Arbeit in einem Entwicklerteam ist von Natur aus eine soziale Tätigkeit bei der Änderungen am Quelltext ständig besprochen, durchgeführt, geprüft und manchmal sogar rückgängig gemacht werden. Versions-Kontroll-Werkzeuge ermöglichen diese Art der Zusammenarbeit.
Mit der Verwendung von Versionskontrolle sind auch Kosten verbunden. Falls Sie die Verwaltung Ihres Versions-Kontroll-Systems nicht an Dritte weitergeben können, haben Sie offensichtlich die Kosten der Verwaltung selbst zu tragen. Wenn Sie täglich mit den Daten arbeiten, werden Sie sie nicht auf die gleiche Art kopieren, verschieben, umbenennen oder löschen können wie gewohnt. Stattdessen müssen Sie dafür das Versions-Kontroll-System verwenden.
Selbst unter der Annahme, dass Sie mit dem Kosten/Nutzen-Verhältnis des Versions-Kontroll-Systems einverstanden sind, sollten Sie keins verwenden, nur weil es das, was Sie möchten, kann. Erwägen Sie, ob andere Werkzeuge Ihnen eher entgegenkommen können. Zum Beispiel wird Subversion, weil es die Daten an alle Beteiligten verteilt, als generisches Verteilsystem missbraucht. Manchmal wird Subversion zum Verteilen von umfangreichen Bildersammlungen, digitaler Musik oder Softwarepaketen verwendet. Das Problem damit ist, dass sich diese Art Daten für gewöhnlich überhaupt nicht verändert. Die Sammlung selber wächst stetig, jedoch werden die einzelnen Dateien der Sammlung nicht verändert. In diesem Fall ist die Benutzung von Subversion zu viel des Guten.[2] Es gibt einfachere Werkzeuge, die hervorragend Daten replizieren, ohne dabei Änderungen mitzuverfolgen, etwa rsync oder unison.
Sobald Sie sich sicher sind, eine Lösung in Form einer Versionskontrolle zu benötigen, werden Sie feststellen, dass kein Mangel an verfügbaren Alternativen besteht. Als Subversion erstmalig entworfen und herausgegeben wurde, war die zentralisierte Versionskontrolle die vorwiegende Methodik der Versionskontrolle – ein einzelner ferner Hauptspeicher für versionierte Daten mit einzelnen Anwendern, die lokal mit flachen Kopien der Versionsgeschichte der Daten arbeiteten. Subversion setzte sich nach seiner ursprünglichen Einführung schnell an die Spitze in diesem Gebiet der Versionskontrolle, gewann weit verbreitete Akzeptanz und ersetzte Installationen vieler älterer Versions-Kontroll-Systeme. Auch heute bleibt seine herausragende Stellung bestehen.
Seitdem hat sich jedoch viel geändert. In den Jahren seit der Geburt des Subversion Projektes hat eine neuere Methodik namens verteilte Versionskontrolle (engl. distributed version control, DVC) ebenso weit verbreitete Aufmerksamkeit und Akzeptanz erlangt. Werkzeuge wie Git (http://git-scm.com/) und Mercurial (http://mercurial-scm.org/) stellten sich schnell an die Spitze n der Rangfolge der verteilten Versions-Kontroll-Systeme (DVCS). Verteilte Versionskontrolle macht sich die wachsende Allgegenwärtigkeit von Hochgeschwindigkeits-Netzverbindungen und geringen Speicherkosten zu Nutze, um einen Ansatz verfügbar zu machen, der sich in wesentlichen Aspekten vom zentralisierten Modell unterscheidet. Zunächst ist das Offensichtlichste, das es keinen zentralen Fernspeicher für versionierte Daten gibt. Vielmehr hält jeder Anwender sehr tiefe – quasi vollständige – lokale Datenspeicher für die Versionsgeschichte vor und arbeitet auch darauf. Zusammenarbeit findet immer noch statt, wird jedoch durch den direkten Austausch von Sammlungen von Änderungen an versionierten Objekten zwischen den lokalen Datenspeichern der Anwender bewerkstelligt, anstatt über einen zentralisierten Datenspeicher. Tatsächlich beruht der Anschein einer kanonischen „Master“-Quelle der versionierten Daten eines Projektes auf Konventionen, ein Status, der durch die verschiedenen Mitarbeiter am Projekt beigemessen wird.
Beide Ansätze haben ihre Vor- und Nachteile. Der vielleicht größte Nutzen der DVCS-Werkzeuge ist das unglaubliche Leistungsvermögen bei tagtäglichen Arbeiten (da der primäre Datenspeicher sich vor Ort befindet) sowie die weitaus bessere Unterstützung des Zusammenführens zwischen Zweigen (da Zusammenführungs-Algorithmen jedenfalls den eigentlichen Kern der Funktionalität von verteilten Versions-Kontroll-Systemen bilden). Der Nachteil ist, dass verteilte Versionskontrolle ein an sich komplizierteres Modell darstellt, das eine nicht zu vernachlässigende Herausforderung für eine bequeme Zusammenarbeit. Außerdem verrichten DVCS-Werkzeuge ihre Arbeit teilweise deshalb so gut, da dem Anwender ein gewisser Grad an Kontrolle vorenthalten wird, der von zentralisierten Systemen frei zur Verfügung gestellt wird: die Möglichkeit, pfadbasierte Zugriffskontrolle zu implementieren, die Flexibilität, individuelle Datenobjekte zu aktualisieren oder aus der Vergangenheit hervorzuholen usw. Glücklicherweise haben viele kluge Organisationen herausgefunden, das es kein religiöser Streit sein muss, und dass Subversion und ein DVCS-Werkzeug wie Git innerhalb der Organisation harmonisch gemeinsam verwendet werden können, wobei jedes Werkzeug zweckorientiert passend eingesetzt wird.
Leider handelt dieses Buch von Subversion, so dass wir nicht versuchen werden, einen vollständigen Vergleich zwischen Subversion und anderen Werkzeugen durchzuführen. Lesern, die die ihr Versions-Kontroll-System wählen dürfen, wird geraten, die verfügbaren Alternativen zu prüfen und sich für diejenige zu entscheiden, die am besten für sie und ihre Mitarbeiter funktioniert. Falls schließlich Subversion das Werkzeug der Wahl ist, gibt es in den folgenden Kapiteln eine Fülle an detaillierten Informationen über dessen Verwendung.
Anfang 2000 begann CollabNet, Inc. (http://www.collab.net) Entwickler zu suchen, die einen Ersatz für CVS schreiben sollten. CollabNet bot[3] eine Software-Suite namens CollabNet Enterprise Edition (CEE) für die Zusammenarbeit an, die auch eine Komponente für Versionskontrolle beinhaltete. Obwohl CEE ursprünglich CVS als Versions-Kontroll-System verwendete, waren die Einschränkungen von CVS von Anfang an offensichtlich, und CollabNet war sich bewusst, dass letztendlich etwas Besseres gefunden werden musste. Unglücklicherweise war CVS der de-facto Standard in der Open-Source-Welt geworden, hauptsächlich deshalb, weil es nichts Besseres gab, zumindest nicht unter einer freien Lizenz. Also beschloss CollabNet, ein vollständig neues Versions-Kontroll-System zu schreiben, welches die grundlegenden Ideen von CVS beibehalten, jedoch die Fehler und Fehlentwicklungen vermeiden sollte.
Im Februar 2000 nahmen sie Verbindung mit Karl Fogel auf, dem Autor von Open Source Development with CVS (Coriolis, 1999), und fragten ihn, ob er an diesem neuen Projekt mitarbeiten wolle. Zufälligerweise besprach Karl bereits einen Entwurf für ein neues Versions-Kontroll-System mit seinem Freund Jim Blandy. Im Jahr 1995 gründeten die beiden Cyclic Software, eine CVS-Beraterfirma, und sie benutzten, obwohl sie die Firma später verkauften, bei ihrer täglichen Arbeit immer noch CVS. Ihre Enttäuschung über CVS veranlasste Jim, sorgfältig über bessere Möglichkeiten zur Verwaltung versionierter Daten nachzudenken. Er hatte sich nicht nur bereits den Subversion-Namen ausgedacht, sondern auch den grundsätzlichen Entwurf der Subversion-Datenablage. Als CollabNet rief, stimmte Karl sofort der Mitarbeit am Projekt zu, und Karl gelang es, dass sein Arbeitgeber Red Hat Software ihn praktisch auf unbestimmte Zeit dem Projekt spendete. CollabNet stellte Karl und Ben Collins-Sussman ein und der detaillierte Entwurfsprozess begann im Mai. Dank einiger Stupser von Brian Behrendorf und Jason Robbins von CollabNet sowie Greg Stein (zu dieser Zeit als unabhängiger Entwickler aktiv im der WebDAV/DeltaV Spezifikationsprozess), zog Subversion schnell eine Gemeinde aktiver Entwickler an. Es stellte sich heraus, dass viele Leute dieselben enttäuschenden Erfahrungen mit CVS gemacht hatten und nun die Gelegenheit begrüßten, etwas daran zu ändern.
Das ursprüngliche Designteam einigte sich auf einige einfache Ziele. Sie wollten kein Neuland in Versions-Kontroll-Methodik betreten, sondern einfach CVS reparieren. Sie beschlossen, dass Subversion dieselben Merkmale und dasselbe Entwicklungsmodell wie CVS haben solle, wobei die Fehler von CVS aber nicht noch einmal gemacht werden sollten. Und obwohl es nicht als ein hundertprozentiger Ersatz für CVS gedacht war, sollte es dennoch ähnlich genug sein, so dass ein leichter Wechsel für einen CVS-Anwender möglich wäre.
Nach vierzehn Monaten Programmierung wurde Subversion am 31. August 2001 „selbstbewirtend“, d.h., die Subversion-Entwickler hörten auf, CVS für den Quellcode von Subversion zu verwenden und benutzten stattdessen Subversion.
Obwohl CollabNet das Projekt startete und immer noch einen großen Batzen der Arbeit finanziert (sie zahlen die Gehälter einiger Vollzeit-Subversion-Entwickler), läuft Subversion wie die meisten Open-Source-Projekte, geführt von einer Anzahl lockerer, transparenter Regeln, die die Meritokratie fördern. Im Jahr 2009 arbeitete CollabNet mit den Subversion-Entwicklern auf das Ziel hin, das Subversion-Projekt in die Apache Software Foundation (ASF) zu integrieren, eine der bekanntesten Kollektiven für Open-Source-Projekte auf der Welt. Subversions technische Wurzeln, Gemeinschaftswerte und Entwicklungspraktiken passten perfekt zur ASF, von deren Mitgliedern viele bereits aktiv an Subversion mitgewirkt haben. Anfang 2010 war Subversion vollständig in die Familie der wichtigsten ASF Projekte aufgenommen, verlegte seine Webpräsenz nach http://subversion.apache.org und wurde in „Apache Subversion“ umbenannt.
Abbildung 1, „Die Architektur von Subversion“ illustriert einen „kilometerhohen“ Blick auf das Design von Subversion.
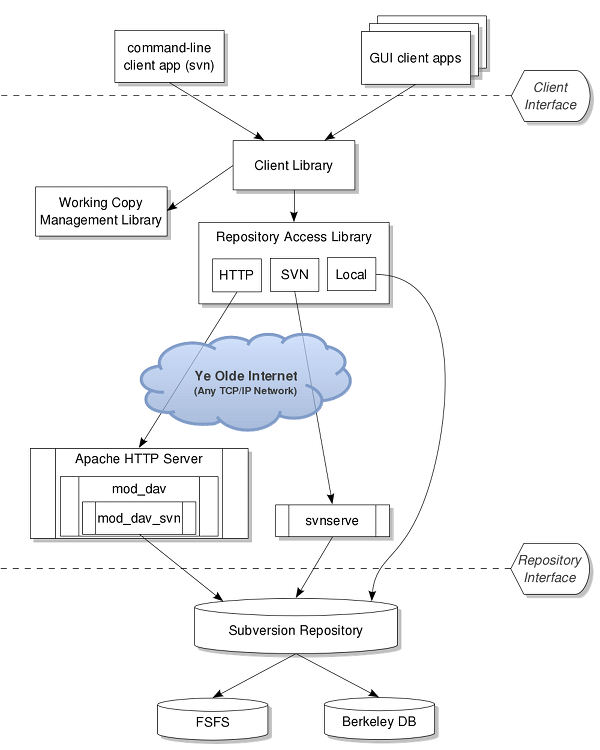
An einem Ende ist das Projektarchiv von Subversion, das die gesamten versionierten Daten enthält. Am anderen Ende ist Ihr Subversion-Client-Programm, das die lokale Spiegelung von Teilen dieser versionierten Daten verwaltet. Zwischen den entgegengesetzten Enden befinden sich mehrere Wege über die Projektarchiv-Zugriffsschicht (RA-Schicht). Einige davon gehen über Computernetzwerke und über Netzwerkserver, die dann auf das Projektarchiv zugreifen. Andere wiederum lassen das Netz links liegen und greifen direkt auf das Projektarchiv zu.
Sobald es installiert ist, hat Subversion eine Anzahl verschiedener Teile. Es folgt ein schneller Überblick über das, was Sie bekommen. Lassen Sie sich nicht beunruhigen, sollten die kurzen Beschreibungen Sie dazu veranlassen, sich am Kopf zu kratzen – es gibt in diesem Buch eine Menge weiterer Seiten, die dem Ziel gewidmet sind, diese Verwirrung zu lindern.
- svn
-
Das Kommandozeilenprogramm
- svnversion
-
Ein Programm, das den Zustand einer Arbeitskopie (durch Revisionen der vorliegenden Objekte) berichtet
- svnlook
-
Ein Werkzeug zur direkten Untersuchung eines Subversion-Projektarchivs
- svnadmin
-
Ein Werkzeug zum Erstellen, Verändern oder Reparieren eines Projektarchivs
- mod_dav_svn
-
Ein Plug-In-Modul für den Apache-HTTP-Server, wird benötigt, um das Projektarchiv über ein Netzwerk verfügbar zu machen
- svnserve
-
Ein spezielles Server-Programm, dass als Hintergrundprozess laufen oder von SSH aufgerufen werden kann; eine weitere Möglichkeit, das Projektarchiv über ein Netzwerk verfügbar zu machen
- svndumpfilter
-
Ein Programm zum Filtern von Subversion-Projektarchiv-Dump-Streams
- svnsync
-
Ein Programm zum inkrementellen Spiegeln eines Projektarchivs über ein Netzwerk
- svnrdump
-
Ein Programm, um die Geschichte eines Projektarchivs über das Netz aus- oder einzulesen
- svnmucc
-
Ein Programm, um mehrere URL-basierte Operationen auf dem Projektarchiv mit einer euinzelnen Übergabe vorzunehmen, ohne dabei eine Arbeitskopie zu verwenden.
Die erste Auflage dieses Buchs wurde von O'Reilly Media im Jahr 2004 veröffentlicht, kurz nachdem Subversion die 1.0 erreicht hatte. Seitdem hat das Subversion-Projekt weiterhin neue Hauptversionen der Software herausgegeben. Hier ist eine kurze Zusammenfassung der umfangreicheren Änderungen seit Subversion 1.0. Beachten Sie, dass es keine komplette Liste ist; um alle Details zu sehen, besuchen Sie die Subversion-Website bei http://subversion.apache.org.
- Subversion 1.1 (September 2004)
-
Release 1.1 führte FSFS ein, eine Projektarchiv-Speicheroption, die auf Dateien basiert. Obwohl das Berkeley-DB-Backend immer noch weitverbreitet ist und unterstützt wird, ist FSFS mittlerweile wegen der niedrigen Einstiegshürde und des minimalen Wartungsbedarfs die Standard-Auswahl für neu erzeugte Projektarchivs. Ebenfalls kam mit diesem Release die Möglichkeit, symbolische Links unter Versionskontrolle zu stellen, das automatische Maskieren von URLs und eine sprachabhängige Benutzerschnittstelle.
- Subversion 1.2 (Mai 2005)
-
Mit Release 1.2 konnten serverseitige Sperren auf Dateien erzeugt und somit der Commit-Zugriff für bestimmte Ressourcen serialisiert werden. Während Subversion immer noch grundsätzlich ein gleichzeitiges Versions-Kontroll-System ist, können bestimmte Arten binärer Dateien (z.B. Kunstobjekte) nicht zusammengeführt werden. Die Sperrmöglichkeit stillt den Bedarf, solche Ressourcen zu versionieren und zu schützen. Zusammen mit dem Sperren kam auch eine vollständige WebDAV-Auto-Versionierungs-Implementierung, die es erlaubt, Subversion-Projektarchivs als Netzwerkverzeichnisse einzuhängen. Schließlich begann Subversion 1.2 einen neuen, schnelleren binären Differenzalgorithmus zu verwenden, um alte Versionen von Dateien zu komprimieren und hervorzuholen.
- Subversion 1.3 (Dezember 2005)
-
Release 1.3 brachte pfadbasierte Autorisierungskontrolle für den svnserve-Server, was einem Merkmal entsprach, das vorher nur im Apache-Server vorzufinden war. Der Apache-Server wiederum bekam einige neue eigene Protokollfunktionen, und die Subversion-API-Bindings für andere Sprachen machten auch große Sprünge vorwärts.
- Subversion 1.4 (September 2006)
-
Release 1.4 führte ein völlig neues Werkzeug – svnsync – ein, um eine Einbahn-Replizierung von Projektarchivs über das Netz vornehmen zu können. Größere Teile der Arbeitskopie-Metadaten wurden überarbeitet, so dass nicht mehr XML benutzt wurde (was sich in erhöhter Geschwindigkeit auf Client-Seite niederschlug), während das Berkeley-DB-Projektarchiv-Backend die Fähigkeit erhielt, sich nach einem Server-Crash automatisch wiederherzustellen.
- Subversion 1.5 (Juni 2008)
-
Release 1.5 brauchte viel länger als vorige Releases, doch das Hauptmerkmal war gigantisch: Halbautomatische Verfolgung des Verzweigens und Zusammenführens. Dies war eine riesige Wohltat für Anwender und schob Subversion weit jenseits der Fähigkeiten von CVS und in die Reihen kommerzieller Mitbewerber wie Perforce und ClearCase. Subversion 1.5 führte auch eine große Anzahl anderer, benutzerorientierter Features ein, wie die interaktive Auflösung von Dateikonflikten, partielle Checkouts, client-seitige Verwaltung von Änderungslisten, eine starke neue Syntax für External-Definitionen und SASL-Authentifizierungsunterstützung für den svnserve-Server.
- Subversion 1.6 (März 2009)
-
Release 1.6 fuhr damit fort, das Verzweigen und Zusammenführen robuster zu machen, indem Baumkonflikte eingeführt wurden. Auch an anderen bestehenden Funktionen wurden Verbesserungen vorgenommen: weitergehende interaktive Optionen zur Konfliktauflösung, rekursives Entfernen und vollständige Unterstützung des Ausschließens für unvollständige Checkouts, dateibasierte Definition von Externals sowie Protokollierungsunterstützung ähnlich wie bei mod_dav_svn. Auch für den Kommandozeilen-Client wurde eine neue Kurzschreibweise zum Referenzieren von Subversion-Projektarchiv.URLs eingeführt.
- Subversion 1.7 (Oktober 2011)
-
Release 1.7 war in erster Linie das Trägermedium für zwei größere interne überarbeitungen von bestehenden Subversion-Komponenten. Die umfangreichste und größte Wirkung entfaltende war die so genannte „WC-NG“ – eine vollständige Neuimplementierung der libsvn_wc Verwaltungsbibliothek für Arbeitskopien. Die zweite Änderung war die Einführung eines geschmeidigeren HTTP-Prototolls für das Zusammenspiel von Subversion Client und Server. Dazu kamen mit Subversion 1.7 auch eine handvoll zusätzlicher Funktionalität, viele Fehlerbehebungen und einige erhebliche Leistungssteigerungen.
- Subversion 1.8 (Juni 2013)
-
In release 1.8 überwacht der Client von Subversion umbenannte Dateien und Verzeichnisse sorgfältiger, und der Befehl svn merge ist nun intelligent genug, um die Option
--reintegrateunnötig zu machen. Bestimmte neue versionierte Eigenschaftswerte können nun von Elternverzeichnissen ererbt werden. Diese Funktionalität erlaubt es einem Projektarchiv nun, Standardwerte für automatische Einstellungen von Eigenschaften und Muster für ignorierbare Dateinamen vorzugeben, und bringt somit Konzistenz in die Gemeinschaft der Nutzer des Projektarchivs, die vorher nur auf sozialem Wege zu bewerkstelligen war. Es gibt auch ein neues, eingebautes Kommandozeilen-Werkzeug zur interaktiven Konfliktauflösung. Wie immer, beinhaltet Subversion 1.8 viel zusätzliche Funktionalität, Fehlerbeseitigungen und Verbesserungen im Verhalten und in der Leistung.