Jede der Kernbibliotheken von Subversion gehört zu einer von
drei Schichten – der Projektarchiv-Schicht, der
Projektarchiv-Zugriffs-Schicht oder der Client-Schicht (siehe
Abbildung 1, „Die Architektur von Subversion“ im Vorwort). Wir
werden diese Schichten gleich untersuchen, doch zunächst wollen
wir eine kurze Zusammenfassung der verschiedenen Bibliotheken
präsentieren. Aus Konsistenzgründen beziehen wir uns auf die
Bibliotheken mit ihren Unix-Namen ohne Dateiendung
(libsvn_fs, libsvn_wc,
mod_dav_svn, usw.).
- libsvn_client
-
Hauptschnittstelle für Client-Programme
- libsvn_delta
-
Prozeduren zum Vergleichen von Bäumen und Byte-Strömen
- libsvn_diff
-
Prozeduren für kontextuelle Vergleiche und Zusammenführungen
- libsvn_fs
-
Gemeinsame Dateisystemprozeduren und Modullader
- libsvn_fs_base
-
Das Berkeley-DB-Dateisystem
- libsvn_fs_fs
-
Das FSFS-Dateisystem
- libsvn_ra
-
Gemeinsame Prozeduren für den Projektarchiv-Zugriff und Modul-Lader
- libsvn_ra_local
-
Modul für den lokalen Projektarchiv-Zugriff
- libsvn_ra_neon
-
Modul für den WebDAV-Projektarchiv-Zugriff
- libsvn_ra_serf
-
Ein weiteres (experimentelles) Modul für den WebDAV-Projektarchiv-Zugriff
- libsvn_ra_svn
-
Projektarchiv-Zugriff über das spezielle Protokoll
- libsvn_repos
-
Projektarchiv-Schnittstelle
- libsvn_subr
-
Verschiedene nützliche Prozeduren
- libsvn_wc
-
Die Bibliothek zur Verwaltung der Arbeitskopie
- mod_authz_svn
-
Apache-Autorisierung-Modul für den Subversion-Zugriff über WebDAV
- mod_dav_svn
-
Apache-Modul, zur Abbildung von WebDAV-Operationen auf solche von Subversion
Die Tatsache, dass das Wort „verschiedene“ nur einmal in der obigen Liste auftaucht, ist ein gutes Zeichen. Das Entwicklerteam von Subversion nimmt es ernst damit, dass Funktionen in den richtigen Schichten und Bibliotheken untergebracht werden. Der vielleicht größte Vorteil des modularen Entwurfs liegt aus Sicht eines Entwicklers in der Abwesenheit von Komplexität. Als Entwickler können Sie sich schnell das „große Bild“ vorstellen, das es Ihnen erlaubt, bestimmte Funktionsbereiche relativ einfach zu lokalisieren.
Ein weiterer Vorteil der Modularität ist die Möglichkeit,
ein gegebenes Modul durch eine völlig neue Bibliothek zu
ersetzen, die dieselbe Programmierschnittstelle implementiert,
ohne den Rest der Code-Basis zu beeinflussen. Eigentlich
passiert das bereits mit Subversion. Die Bibliotheken
libsvn_ra_local,
libsvn_ra_neon,
libsvn_ra_serf und
libsvn_ra_svn implementieren alle die
gleiche Schnittstelle und funktionieren als Plug-In für
libsvn_ra. Alle vier kommunizieren mir der
Projektarchiv-Schicht – libsvn_ra_local
verbindet sich direkt mit dem Projektarchiv; die drei anderen
machen das über das Netz. Die Bibliotheken
libsvn_fs_base und
libsvn_fs_fs sind noch ein Paar, das die
gleiche Funktion auf verschiedene Art implementiert –
beide sind Plug-Ins der gemeinsamen Bibliothek
libsvn_fs.
Auch der Client selber unterstreicht die Vorteile der
Modularität beim Entwurf von Subversion. Die meisten Funktionen,
die für den Entwurf eines Subversion-Clients benötigt werden,
sind in der Bibliothek libsvn_client
vorhanden (siehe „Client-Schicht“). Obwohl das
Subversion-Paket lediglich das Kommandozeilenprogramm
svn mitbringt, stellen mehrere Programme von
Drittanbietern verschiedene Spielarten graphischer
Benutzeroberflächen zur Verfügung, die die gleichen APIs wie der
Standard-Kommandozeilen-Client verwenden. Diese Art der
Modularität hat eine große Rolle bei der Verbreitung verfügbarer
Subversion-Clients sowie Integrationen in Entwicklungsumgebungen
gespielt und durch Erweiterungen zur enormen Akzeptanzrate von
Subversion selbst beigetragen.
Wenn wir uns auf die Projektarchiv-Schicht von Subversion
beziehen, reden wir üblicherweise über zwei grundlegende
Konzepte – die Implementierung des versionierten
Dateisystems (auf das mittels libsvn_fs
zugegriffen wird, unterstützt durch dessen Plug-Ins
libsvn_fs_base und
libsvn_fs_fs) und die Logik des
Projektarchivs, die es umgibt (implementiert in
libsvn_repos). Diese Bibliotheken liefern
die Speicher- und Auswertungsmechanismen für die verschiedenen
Revisionen Ihrer versionskontrollierten Daten. Diese Schicht
ist mit der Client-Schicht über die
Projektarchiv-Zugriffs-Schicht verbunden und stellt, aus der
Sicht des Benutzers von Subversion, das „andere Ende der
Leitung“ dar.
Das Dateisystem von Subversion ist kein Dateisystem auf Kernel-Ebene, das im Betriebssystem installiert würde (so wie Linux ext3 oder NTFS), sondern ein virtuelles Dateisystem. Anstatt „Dateien“ und „Verzeichnisse“ als echte Dateien und Verzeichnisse abzulegen (in denen Sie mit Ihrem bevorzugten Shell-Programm navigieren können), verwendet es eins von zwei verfügbaren abstrakten Speicherverfahren – entweder eine Berkeley-DB-Datenbankumgebung oder eine Repräsentation über einfache Dateien. (Um mehr über die zwei Verfahren kennenzulernen, siehe „Auswahl der Datenspeicherung“.) Es hat seitens der Entwicklergemeinschaft ein beträchtliches Interesse bestanden, künftigen Versionen von Subversion die Fähigkeit zu verleihen, andere Datenbanksysteme zu verwenden, etwa über einen Mechanismus wie Open Database Connectivity (ODBC). Tatsächlich hat Google etwas ähnliches gemacht, bevor der Dienst Google Code Project Hosting gestartet wurde: Mitte 2006 wurde angekündigt, dass Mitarbeiter des Open-Source-Teams ein neues proprietäres Dateisystem-Plug-In für Subversion geschrieben hätten, welches Googles höchstskalierbare Bigtable-Datenbank zum Speichern verwendet.
Die von libsvn_fs exportierte
Dateisystem-Programmierschnittstelle enthält die Funktionen,
die Sie auch von jeder anderen Programmierschnittstelle für
ein Dateisystem erwarten würden – Sie können Dateien und
Verzeichnisse anlegen und löschen, kopieren und verschieben,
den Inhalt verändern usw. Sie besitzt auch Funktionen, die
nicht so verbreitet sind, wie etwa die Fähigkeit, Metadaten
(„Eigenschaften“) an jede Datei oder jedes
Verzeichnis anzufügen, zu verändern oder zu entfernen. Zudem
ist das Dateisystem von Subversion ein versioniertes
Dateisystem, d.h., während Sie Ihren Verzeichnisbaum ändern,
merkt sich Subversion, wie er vor Ihren Änderungen ausgesehen
hat. Und vor den vorhergehenden Änderungen. Und davor. Und so
weiter durch die gesamte versionierte Zeitachse bis zu dem
Moment (und kurz davor), an dem Sie das erste Mal etwas dem
Dateisystem hinzugefügt hatten.
Alle Änderungen, die Sie an Ihrem Baum vornehmen, geschehen im Kontext einer Subversion-Übergabe-Transaktion. Das Folgende ist eine vereinfachte allgemeine Vorgehensweise beim Ändern Ihres Dateisystems:
-
Eine Subversion-Übergabe-Transaktion starten.
-
Nehmen Sie Ihre Änderungen vor (Ergänzungen, Löschungen, Änderungen an Eigenschaften usw.).
-
Schließen Sie Ihre Transaktion ab.
Sobald Sie Ihre Transaktion abgeschlossen haben, werden Ihre Änderungen am Dateisystem dauerhaft als historische Artefakte gespeichert. Jeder dieser Zyklen erzeugt eine einzelne neue Revision Ihres Baums, und jede Revision ist für immer verfügbar als unveränderliche Momentaufnahme „der Dinge, wie sie mal waren“.
Die meisten von der Dateisystemschnittstellen angebotenen
Funktionen drehen sich um Aktionen, die auf einzelnen
Dateisystempfaden stattfinden. Von außerhalb des Dateisystems
betrachtet heißt das, dass der Hauptmechanismus zur
Beschreibung und Handhabung einzelner Datei- und
Verzeichnisrevisionen über Pfad-Zeichenketten wie
/foo/bar erfolgt, genauso, als ob Sie
Dateien und Verzeichnisse über Ihr bevorzugtes Shell-Programm
ansprechen würden. Sie fügen neue Dateien und Verzeichnisse
hinzu, indem Sie die künftigen Pfade an die passenden
API-Funktionen übergeben. Sie können Informationen über den
gleichen Mechanismus abrufen.
Im Gegensatz zu den meisten Dateisystemen reicht jedoch ein Pfad alleine nicht aus, um in Subversion eine Datei oder ein Verzeichnis zu identifizieren. Stellen Sie sich einen Verzeichnisbaum als ein zweidimensionales System vor, in dem Nachbarknoten eine Art horizontale und die Unterverzeichnisse eines Knotens eine vertikale Bewegung repräsentieren. Abbildung 8.1, „Dateien und Verzeichnisse in zwei Dimensionen“ zeigt genau das als typische Repräsentation eines Baums.
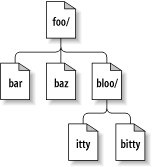
Der Unterschied ist hier, dass das Dateisystem von
Subversion eine raffinierte dritte Dimension hat, die den
meisten Dateisystemen fehlt – Zeit![65] Fast
jede Funktion der Dateisystemschnittstelle, die ein
path-Argument erwartet, benötigt auch
ein root-Argument. Dieses Argument vom
Typ svn_fs_root_t beschreibt entweder eine
Revision oder eine Subversion-Transaktion (welche einfach eine
Revision in Arbeit ist) und stellt die dritte Dimension des
Kontexts zur Verfügung, die benötigt wird, um den Unterschied
zwischen /foo/bar in Revision 32 und
demselben Pfad in Revision 98 zu verstehen. Abbildung 8.2, „Versionierung der Zeit – die dritte Dimension!“ zeigt die
Revisionsgeschichte als eine zusätzliche Dimension im
Subversion-Dateisystem-Universum.
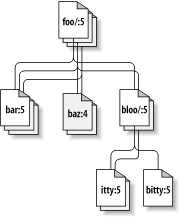
Wie bereits erwähnt, mutet die
libsvn_fs-API wie jedes andere
Dateisystem an, außer dass es diese wundervolle
Versionierungsmöglichkeit hat. Sie wurde entworfen, um für
jedes Programm nutzbar zu sein, das an einem versionierten
Dateisystem interessiert ist. Nicht nur zufällig hat
Subversion selbst Interesse an dieser Funktion. Doch obwohl
die Unterstützung der Dateisystemschnittstelle ausreichend für
die einfache Versionierung von Dateien und Verzeichnissen ist,
braucht Subversion mehr – und hier hat
libsvn_repos seinen Auftritt.
Die Subversion-Projektarchiv-Bibliothek
(libsvn_repos) sitzt (logisch) oberhalb
der libsvn_fs-API und stellt zusätzliche
Funktionen zur Verfügung, die über die grundlegende Logik
eines versionierten Dateisystem hinausgehen. Sie umhüllt nicht
alle Dateisystemfunktionen vollständig – lediglich
bestimmte größere Schritte im allgemeinen Zyklus der
Dateisystemaktivität. Einige dieser Schritte umfassen die
Erzeugung und den Abschluss von Subversion-Transaktionen und
die Änderung von Revision-Eigenschaften. Diese besonderen
Ereignisse werden durch die Projektarchiv-Schicht gekapselt, da
mit ihnen Hooks verknüpft sind. Ein System mit
Projektarchiv-Hooks hat strenggenommen nichts mit der
Implementierung eines versionierten Dateisystems zu tun, so
dass es in der Projektarchiv-Bibliothek untergebracht ist.
Der Hook-Mechanismus ist aber nur ein Grund für die
Abstraktion einer eigenständigen Projektarchiv-Bibliothek vom
Rest des Dateisystemcodes. Die API
libsvn_repos stellt mehrere andere
wichtige Werkzeuge für Subversion zur Verfügung. Darunter
fallen Fähigkeiten, um
-
ein Subversion-Projektarchiv und das darin enthaltene Dateisystem zu erzeugen, zu öffnen, zu zerstören und hierauf Schritte zur Wiederherstellung auszuführen.
-
die Unterschiede zwischen zwei Dateisystem-Bäumen zu beschreiben.
-
die Übergabe-Protokollnachrichten aller (oder einiger) Revisionen abzurufen, in denen eine Menge aus Dateien im Dateisystem verändert wurde.
-
einen menschenlesbaren „Auszug“ des Dateisystems zu erzeugen — eine vollständige Repräsentation der Revisionen im Dateisystem.
-
dieses Auszugsformat zu lesen und die Revisionen in ein anderes Subversion-Projektarchiv zu laden.
Während sich Subversion weiterentwickelt, wird die Projektarchiv-Bibliothek gemeinsam mit der Dateisystem-Bibliothek wachsen und erweiterte Funktionen und konfigurierbare Optionen unterstützen.
Wenn die Subversion-Projektarchiv-Schicht das „andere
Ende der Leitung“ repräsentiert, stellt die
Projektarchiv-Zugriffs-Schicht (RA) die Leitung selbst dar. Ihre
Aufgabe ist das Umherschaufeln von Daten zwischen den
Client-Bibliotheken und dem Projektarchiv. Diese Schicht umfasst
die Bibliothek libsvn_ra zum Laden von
Modulen, die eigentlichen RA-Module (momentan
libsvn_ra_neon,
libsvn_ra_local,
libsvn_ra_serf und
libsvn_ra_svn) und alle zusätzlichen
Bibliotheken, die von einer oder mehreren dieser RA-Module
benötigt werden (so wie das Apache-Modul
mod_dav_svn oder
svnserve, der Server von
libsvn_ra_svn).
Da Subversion URLs zum Identifizieren seiner
Projektarchiv-Quellen benutzt, wird der Protokollteil des
URL-Schemas (normalerweise file://,
http://, https://,
svn:// oder svn+ssh://)
verwendet, um festzustellen, welches RA-Modul die
Kommunikation abwickelt. Jedes Modul hinterlegt eine Liste von
Protokollen, die es „versteht“, so dass der
RA-Lader zur Laufzeit bestimmen kann, welches Modul für die
aktuelle Aufgabe benutzt werden kann. Sie können feststellen,
welche RA-Module für der Kommandozeilen-Client zur Verfügung
stehen und welche Protokolle sie zu verstehen vorgeben, indem
Sie svn --version aufrufen:
$ svn --version svn, Version 1.7.0 übersetzt Nov 15 2011, 10:10:24 Copyright (C) 2011 The Apache Software Foundation. This software consists of contributions made by many people; see the NOTICE file for more information. Subversion is open source software, see http://subversion.apache.org/ Die folgenden ZugriffsModule (ZM) für Projektarchive stehen zur Verfügung: * ra_neon : Modul zum Zugriff auf ein Projektarchiv über das Protokoll WebDAV mittels Neon. - behandelt Schema »http« - behandelt Schema »https« * ra_svn : Modul zum Zugriff auf ein Projektarchiv über das svn-Netzwerkprotokoll. - mit Cyrus-SASL-Authentifizierung - behandelt Schema »svn« * ra_local : Modul zum Zugriff auf ein Projektarchiv auf der lokalen Festplatte - behandelt Schema »file« * ra_serf : Modul zum Zugriff auf ein Projektarchiv über das Protokoll WebDAV mittels serf. - behandelt Schema »http« - behandelt Schema »https« $
Die von der RA-Schicht exportierte API beinhaltet
Funktionen, die zum Senden und Empfangen versionierter Daten
zum und vom Projektarchiv notwendig sind. Jedes der
verfügbaren RA-Plug-Ins kann diese Aufgabe mithilfe eines
besonderen Protokolls erledigen –
libsvn_ra_neon sowie
libsvn_ra_serf kommunizieren über
HTTP/WebDAV (optional mit SSL-Verschlüsselung) mit einem
Apache-HTTP-Server auf dem das Subversion-Server-Modul
mod_dav_svn läuft;
libsvn_ra_svn kommuniziert über ein
maßgeschneidertes Netzprotokoll mit dem
svnserve Programm usw.
Für diejenigen, die über ein völlig anderes Protokoll auf das Projektarchiv zugreifen möchten, sei gesagt, dass genau das der Grund für die Modularisierung der Projektarchiv-Zugriffsschicht ist. Entwickler können einfach eine neue Bibliothek schreiben, die auf der einen Seite die RA-Schnittstelle implementiert und auf der anderen Seite mit dem Projektarchiv kommuniziert. Ihre neue Bibliothek kann bestehende Netzprotokolle verwenden, oder Sie können Ihr eigenes erfinden. Sie könnten Aufrufe über Interprozess-Kommunikation (IPC) machen oder – mal etwas verrücktes – sogar ein auf E-Mail basiertes Protokoll implementieren. Subversion liefert die APIs, Sie sorgen für die Kreativität.
Auf der Client-Seite finden alle Aktionen in der Subversion-Arbeitskopie statt. Der größte Teil der in den Client-Bibliotheken implementierten Funktionen dient dem alleinigen Zweck, die Arbeitskopien zu verwalten – Verzeichnisse voller Dateien und anderer Unterverzeichnisse, die als eine Art lokaler, editierbarer „Spiegelung“ einer oder mehrere Orte im Projektarchiv dienen – und Änderungen an die RA-Schicht weiterzugeben oder von ihr zu empfangen.
Die Bibliothek für die Arbeitskopie von Subversion,
libsvn_wc, ist direkt dafür
verantwortlich, die Daten in den Arbeitskopien zu verwalten.
Hierzu speichert die Bibliothek Verwaltungsinformationen zur
Arbeitskopie in einem besonderen
Unterverzeichnis. Dieses Unterverzeichnis namens
.svn kommt in jeder
Arbeitskopie vor und beinhaltet zahlreiche weitere Dateien und
Verzeichnisse, in denen der Zustand aufgezeichnet wird und die
einen privaten Arbeitsbereich für Verwaltungsaufgaben liefern.
Für diejenigen, die CVS kennen, ist der Zweck des
Unterverzeichnisses .svn ähnlich den in
CVS-Arbeitskopien zu findenden Verwaltungsverzeichnissen
CVS.
Die Subversion-Client-Bibliothek,
libsvn_client, besitzt die weitestgehende
Verantwortlichkeit; ihre Aufgabe ist es, die Funktionen der
Arbeitskopie-Bibliothek mit denen der RA-Schicht zu vermischen
und eine API auf höchster Ebene für Anwendungen zur Verfügung
zu stellen, die allgemeine Versionskontrollaktionen
durchführen wollen. Beispielsweise erwartet die Funktion
svn_client_checkout() einen URL als
Argument. Sie leitet diesen URL an die RA-Schicht weiter und
startet eine authentifizierte Sitzung mit einem bestimmten
Projektarchiv. Dann fragt sie das Projektarchiv nach einem
bestimmten Baum und schickt diesen Baum an die
Arbeitskopie-Bibliothek, die dann die gesamte Arbeitskopie auf
die Platte schreibt (samt
.svn-Verzeichnissen und allem Drum und
Dran).
Die Client-Bibliothek ist so aufgebaut, dass sie von jeder
Anwendung verwendet werden kann. Obwohl der Quelltext von
Subversion einen Standard-Kommandozeilen-Client enthält,
sollte es sehr einfach sein, eine beliebige Anzahl von
graphischen Clients zu schreiben, die auf die
Client-Bibliothek aufsetzen. Neue graphische Oberflächen (oder
eigentlich jeder neue Client) für Subversion brauchen keine
sperrigen Hüllen um den enthaltenen Kommandozeilen-Client zu
sein – sie haben über die API von
libsvn_client vollen Zugriff auf die
Funktionen, Daten und Rückrufmechanismen die der
Kommandozeilen-Client benutzt. Tatsächlich enthält der
Quelltext von Subversion ein kleines C-Programm (das Sie unter
tools/examples/minimal_client.c finden)
welches beispielhaft zeigt, wie die Subversion API verwendet
wird, um ein einfaches Client-Programm zu erzeugen.
[65] Wir sind uns bewusst, dass das für Science-Fiction-Fans, die lange Zeit davon ausgegangen sind, dass Zeit eigentlich die vierte Dimension ist, ein Schock sein kann, und wir bitten um Entschuldigung, falls die Geltendmachung einer unterschiedlichen Theorie unsererseits zu einem seelischen Schock führen sollte.