Ein Versionskontrollsystem (oder Revisionskontrollsystem) ist ein System, das inkrementelle Versionen (oder Revisionen) von Dateien und, in manchen Fällen, Verzeichnissen über die Zeit hinweg verfolgt. Natürlich ist es für sich nicht sehr interessant, die verschiedenen Versionen eines Anwenders (oder einer Gruppe von Anwendern) zu verfolgen. Was ein Versionskontrollsystem nützlich macht, ist die Tatsache, dass es Ihnen erlaubt, die Änderungen zu untersuchen, die zu jeder dieser Versionen geführt haben und es ermöglicht, erstere jederzeit wieder aufzurufen.
In diesem Abschnitt werden wir einige Komponenten und Konzepte von Versionskontrollsystemen auf ziemlich hohem Niveau vorstellen. Wir werden uns auf moderne Versionskontrollsysteme beschränken – in der heutigen vernetzten Welt hat es wenig Sinn, Versionskontrollsystemen eine Berechtigung einzuräumen, die nicht über Netze hinweg arbeiten können.
Im Kern eines Versionskontrollsystems ist ein Projektarchiv, das der zentrale Speicher der Daten dieses Systems ist. Das Projektarchiv speichert Informationen gewöhnlicherweise in Form eines Dateisystembaumes, eine Hierarchie aus Dateien und Verzeichnissen. Eine beliebige Anzahl von Clients verbindet sich mit dem Projektarchiv und liest oder schreibt diese Dateien. Durch den Schreibvorgang, macht ein Client Informationen für andere verfügbar. Durch den Lesevorgang bekommt der Client Informationen von anderen zur Verfügung gestellt. Abbildung 1.1, „Ein typisches Client/Server System“ verdeutlicht das.
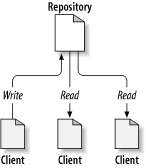
Warum ist das interessant? Bis zu diesem Punkt hört sich das wie die Definition eines typischen Datei-Servers an. Und tatsächlich, das Projektarchiv ist eine Art von Datei-Server, aber nicht von der Art, die Sie kennen. Was das Subversion-Projektarchiv so speziell macht ist, dass es sich während die Dateien im Projektarchiv geändert werden jede Version jener Dateien merkt.
Wenn ein Client Daten aus dem Projektarchiv liest, bekommt der Client üblicherweise nur die letzte Version des Dateisystem-Baumes zu sehen. Was ein Versionskontrollsystem aber interessant macht, ist darüber hinaus die Fähigkeit, vorherige Zustände des Dateibaums aus dem Projektarchiv abzurufen. Ein Versionskontrollsystem kann historische Fragen stellen, wie „Was beinhaltete das Verzeichnis am letzten Mittwoch?“ und „Wer war die Person, die als letztes die Datei geändert hat und welche Änderungen hat sie gemacht?“. Diese Art von Fragen sind die Grundlage eines Versionskontrollsystems.
Der Wert eines Versionskontrollsystems rührt von der Tatsache her, dass es Versionen von Dateien und Verzeichnissen verfolgt, doch der Rest des Software-Universums arbeitet nicht auf „Versionen von Dateien und Verzeichnissen“. Die meisten Programme wissen, wie mit einer einzelnen Version eines bestimmten Dateityps umgegangen wird. Wie arbeitet also ein Anwender eines Versionskontrollsystems konkret mit einem abstrakten – und oft entfernten – Projektarchiv voll mit mehreren Versionen verschiedener Dateien? Wie schaffen es seine oder ihre Textbearbeitungs-Software, Präsentations-Software, Quelltexteditoren, Web-Design-Software oder sonstigen Programme, die alle nur mit einfachen Dateien umgehen können, Zugriff auf solche Dateien zu bekommen? Die Antwort findet sich im Versionskontroll-Konstrukt, das als Arbeitskopie bekannt ist.
Eine Arbeitskopie ist buchstäblich eine lokale Kopie einer bestimmten Version der vom VCS verwalteten Anwenderdaten mit der der Anwender frei arbeiten kann. Arbeitskopien[5] sehen für andere Software aus wie alle anderen lokalen Verzeichnisse voller Dateien, so dass diese Programme nicht „versionskontroll-bewusst“ sein müssen, um die Daten zu lesen und zu schreiben. Die Aufgabe, die Arbeitskopie zu verwalten und Änderungen an ihrem Inhalt zum und vom Projektarchiv zu übergeben, fällt genau der Client-Software des Versionskontrollsystems zu.
Wenn die primäre Mission eines Versionskontrollsystems darin besteht, die unterschiedlichen Versionen digitaler Informationen über die Zeit hinweg zu verfolgen, liegt eine sehr nahe sekundäre Mission darin, das kollaborative Bearbeiten und Teilen dieser Daten zu ermöglichen. Jedoch verwenden unterschiedliche Systeme auch unterschiedliche Strategien, um dies zu bewerkstelligen. Aus einer Reihe von Gründen ist es wichtig, diese Unterschiede zu verstehen. Zunächst hilft es dabei, bestehende Versionskontrollsysteme zu vergleichen und gegenüberzustellen, falls Ihnen andere Systeme begegnen, die Subversion ähneln. Darüber hinaus wird es Ihnen helfen, Subversion effektiver zu benutzen, da Subversion selbst eine Reihe unterschiedlicher Arbeitsweisen unterstützt.
Alle Versionskontrollsysteme haben das gleiche fundamentale Problem zu lösen: Wie soll es Anwendern erlaubt werden, Informationen zu teilen, aber sie davor zu bewahren, sich gegenseitig auf die Füße zu treten? Es ist allzu einfach, die Änderungen eines anderen im Projektarchiv zu überschreiben.
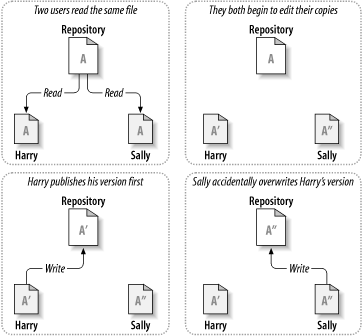
Stellen Sie sich einmal folgendes Szenario in Abbildung 1.2, „Das zu vermeidende Problem“ vor: Zwei Kollegen, Harry und Sally, haben sich entschieden, dieselbe Datei zur gleichen Zeit zu bearbeiten. Harry speichert seine Änderungen zuerst im Projektarchiv, es ist aber möglich, dass Sally nur einige Augenblicke später seine Datei mit ihrer überschreibt. Harrys Änderungen der Datei sind zwar nicht für immer verloren (da das System jede Änderung aufzeichnet), aber alle seine Änderungen sind in Sallys später gespeicherter Version der Datei nicht vorhanden, da Sally diese Änderungen noch gar nicht kannte. Das heißt, dass Harrys Arbeit doch verloren ist, zumindest in der neuesten Version der Datei, und das vermutlich aus Versehen. Eine solche Situation wollen wir auf alle Fälle vermeiden.
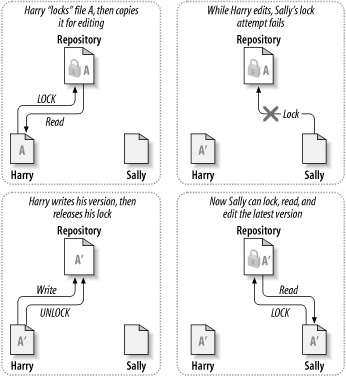
Viele Versionskontrollsysteme verwenden ein Sperren-Ändern-Entsperren-Modell um zu verhindern, dass verschiedene Autoren sich gegenseitig die Änderungen löschen. Bei diesem Modell erlaubt das Projektarchiv nur jeweils einem Programmierer den Zugriff auf eine Datei. Harry müsste also die Datei sperren, ehe er anfängt, seine Änderungen einzugeben. Wenn Harry die Datei gesperrt hat, kann Sally sie nicht ebenfalls sperren und daher auch nichts ändern. Sie kann die Datei in der Zeit nur lesen und darauf warten, dass Harry mit seiner Arbeit fertig ist und die Datei entsperrt. Abbildung 1.3, „Die Sperren-Ändern-Entsperren-Lösung“
Das Problem bei einem Sperren-Ändern-Entsperren-Modell liegt in seinen Beschränkungen, die oft zu schier unüberwindlichen Hindernissen führen können.
-
Das Sperren kann zu administrativen Problemen führen. Vielleicht sperrt Harry eine Datei und vergisst dann, sie zu entsperren. In der Zwischenzeit sind Sally, die ebenfalls Änderungen an dieser Datei durchführen will, die Hände gebunden. Und dann geht Harry in Urlaub. Nun muss Sally sich an einen Administrator wenden, um die Datei entsperrt zu bekommen. Das Ergebnis sind unnötige Verzögerungen und vergeudete Zeit.
-
Das Sperren kann zu einer unnötigen Serialisierung führen. Was ist, wenn Harry z. B. den Anfang einer Textdatei bearbeiten will, während Sally einfach nur das Ende ändern möchte? Diese Änderungen würden sich überhaupt nicht gegenseitig beeinflussen und könnten problemlos gleichzeitig durchgeführt werden, vorausgesetzt, sie würden anschließend vernünftig zusammengefasst. Es gibt in dieser Situation keinen Grund, der Reihe nach zu arbeiten.
-
Das Sperren kann zu einem falschen Gefühl von Sicherheit führen. Angenommen Harry sperrt und bearbeitet Datei A, während Sally gleichzeitig Änderungen an Datei B durchführt. Was ist, wenn A und B voneinander abhängig sind und die jeweiligen Änderungen nicht kompatibel sind? Plötzlich funktioniert das Zusammenspiel zwischen A und B nicht mehr. Das System des Sperrens hat dieses Problem nicht verhindert, doch hat es fälschlicherweise zu einem Gefühl der Sicherheit geführt. Es ist leicht, sich vorzustellen, dass Harry und Sally der Meinung waren, dass jeder von ihnen eine eigenständige, voneinander unabhängige Änderung durchgeführt hat und dass das Sperren dazu geführt hat, dass sie ihre inkompatiblen Änderungen nicht vorher miteinander besprochen haben. Sperren ist oft ein Ersatz für echte Kommunikation.
Subversion, CVS und viele andere Versionskontrollsysteme benutzen ein Kopieren–Ändern–Zusammenfassen-Modell als Alternative zum Sperren. In diesem Modell verbindet sich jeder Client der Anwender mit dem Projektarchiv und erzeugt eine persönliche Arbeitskopie. Dann arbeiten die Anwender gleichzeitig und unabhängig voneinander an ihren privaten Kopien. Am Ende werden dann alle Einzelkopien zu einer neuen, aktuellen Version zusammengeführt. Das Versionskontrollsystem hilft oft bei dieser Zusammenführung, aber letztlich ist der Mensch dafür verantwortlich, das es korrekt abläuft.
Hier ist ein Beispiel: Harry und Sally haben sich jeweils eine eigene Arbeitskopie des im Projektarchiv vorhandenen Projektes geschaffen. Beide arbeiten nun an der selben Datei A innerhalb ihrer jeweiligen Kopien. Sally speichert ihre Version zuerst im Projektarchiv ab. Wenn Harry später ebenfalls versucht, seine Änderungen zu speichern, informiert ihn das Projektarchiv, das seine Datei A nicht mehr aktuell ist. Das bedeutet, dass seitdem er sich seine Kopie erschaffen hat, sind irgendwelche Änderungen aufgetreten. Also bittet Harry seinen Client darum, diese neuen Änderungen in seine Arbeitskopie der Datei A einzuarbeiten. Die Möglichkeit besteht, dass Sallys Änderungen mit seinen nicht überlappen, wenn er also alle Änderungen eingearbeitet hat, kann er seine Arbeitskopie zurück in das Projektarchiv speichern. Die Abbildungen Abbildung 1.4, „„Kopieren – Ändern – Zusammenfassen“ - Lösung“ und Abbildung 1.5, „„Kopieren – Ändern – Zusammenfassen“ - Lösung (Fortsetzung)“ zeigen diesen Prozess.
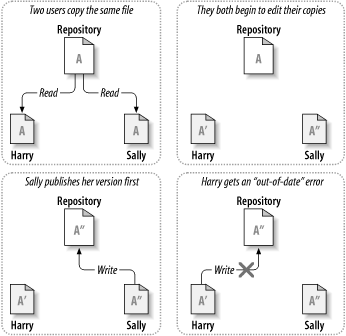
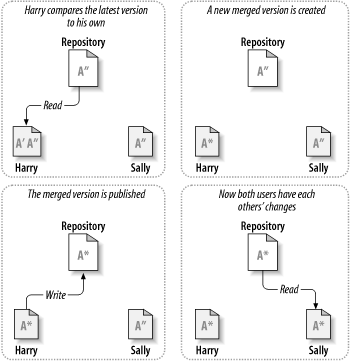
Was aber passiert, wenn Sallys Änderungen mit Harrys kollidieren? Diese Situation wird Konflikt genannt und ist normalerweise kein allzu großes Problem. Wenn Harry Sallys Änderungen in seine Datei einpflegen lassen will, werden in seiner Datei die miteinander in Konflikt stehenden Änderungen gekennzeichnet, er kann sämtliche Änderungen sehen und manuell zwischen ihnen wählen. Das Programm löst solche Konfliktsituationen nicht automatisch, nur Menschen sind in der Lage, die Probleme zu erkennen und die nötigen intelligenten Änderungen durchzuführen. Wenn Harry die Konfliktsituationen – vielleicht nach einer kurzen Diskussion mit Sally – gelöst hat, kann er seine Datei problemlos ins Projektarchiv speichern.
Dieses Kopieren-Ändern-Zusammenfassen-Modell (engl. copy-modify-merge model) klingt vielleicht ein wenig chaotisch, in der Praxis aber läuft es völlig glatt. Die einzelnen Anwender können parallel arbeiten, ohne einander in die Quere zu kommen oder unnötig warten zu müssen. Wenn sie an den selben Dateien arbeiten, zeigt es sich meistens, dass ihre jeweiligen Änderungen einander überhaupt nicht stören, wirkliche Konflikte sind selten. Und die Zeit, die es beansprucht, eine solche Konfliktsituation zu lösen, ist meist wesentlich kürzer als der Zeitverlust, der durch das Sperren auftritt.
Am Ende läuft alles auf einen kritischen Faktor hinaus: Kommunikation zwischen den Anwendern. Wenn diese Kommunikation eher spärlich abläuft, häufen sich sowohl semantische als auch syntaktische Konflikte. Kein System kann Anwender dazu zwingen, vernünftig miteinander zu kommunizieren und kein System kann semantische Konflikte erkennen. Also hat es auch keinen Sinn, sich in dem falschen Gefühl von Sicherheit zu wiegen, dass das Sperren Konflikte irgendwie vermeiden könnte. In der Praxis verringert das System des Sperrens mehr als andere die Produktivität.
[5] Der Begriff „Arbeitskopie“ kann allgemein auf die lokale Instanz einer jeden Dateiversion angewendet werden. Die meisten Leute verwenden den Begriff aber, wenn sie sich auf einen kompletten Verzeichnisbaum beziehen, der Dateien und Verzeichnisse enthält, die vom Versionskontrollsystem verwaltet werden.